
Java基础面试
✅Arrays.sort是使用什么排序算法实现的?
典型回答
Arrays.sort是Java中提供的对数组进行排序的方法,根据参数类型不同,它提供了很多重载方法:
1 | public static void sort(Object[] a) ; |
而针对不同的参数类型,采用的算法也不尽相同,首先,对于比较常见的基本数据类型(如int、double、char等)的数组,就是采用JDK 1.7中引入的**“双轴快速排序”(Dual-Pivot QuickSort)**:
1 | public static void sort(int[] a) { |
这里的DualPivotQuicksort.sort就是双轴快速排序的具体实现。
双轴快速排序是对传统快速排序的改进,它通过选择两个轴值来划分数组,并在每个划分区域中进行递归排序。这种算法通常比传统的快速排序更快,特别是在大量重复元素的情况下。双轴快速排序算法是在JDK7中引入的,并在后续版本中进行了优化和改进。
而针对另外一种类型,对于对象数组的排序,它支持两种排序方式,即归并排序和TimSort:
1 | // 1.7以前 |
这里面的MergeSort指的就是归并排序,这个算法是老版本中设计的,后续的版本中可能会被移除,新版本中主要采用TimSort算法。
TimSort 是一种混合排序算法,结合了归并排序(Merge Sort)和插入排序(Insertion Sort)的特点。
关于各种算法的原理和实现方式,因为不是我们八股文的重点,关于算法部分大家自行学习吧,这里就不展开了,大家想了解的可以自己去看一下相关算法的实现。
✅BigDecimal(double)和BigDecimal(String)有什么区别?
典型回答
有区别,而且区别很大。
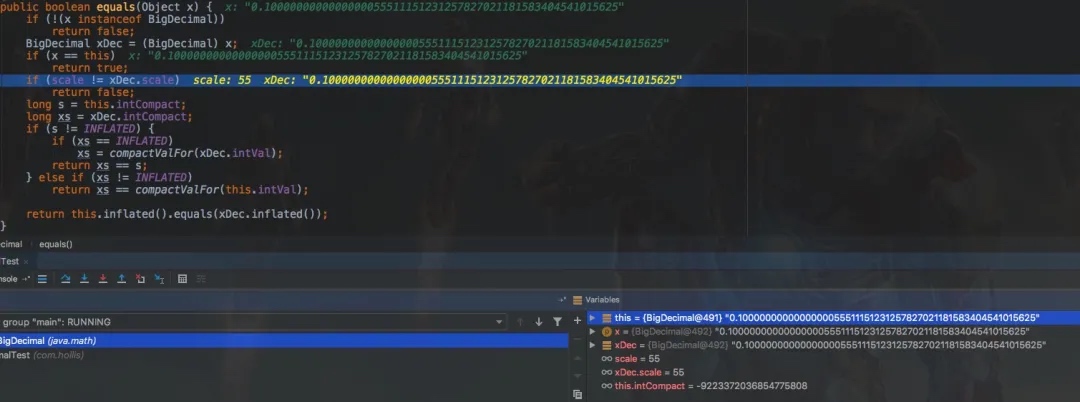
因为double是不精确的,所以使用一个不精确的数字来创建BigDecimal,得到的数字也是不精确的。如0.1这个数字,double只能表示他的近似值。
所以,当我们使用new BigDecimal(0.1)创建一个BigDecimal 的时候,其实创建出来的值并不是正好等于0.1的。
而是0.1000000000000000055511151231257827021181583404541015625。这是因为double自身表示的只是一个近似值。
而对于BigDecimal(String) ,当我们使用new BigDecimal(“0.1”)创建一个BigDecimal 的时候,其实创建出来的值正好就是等于0.1的。
那么他的标度也就是1
扩展知识
在《阿里巴巴Java开发手册》中有一条建议,或者说是要求:

BigDecimal如何精确计数?
如果大家看过BigDecimal的源码,其实可以发现,实际上一个BigDecimal是通过一个”无标度值”和一个”标度”来表示一个数的。
无标度值(Unscaled Value):这是一个整数,表示BigDecimal的实际数值。
标度(Scale):这是一个整数,表示小数点后的位数。
BigDecimal的实际数值计算公式为:unscaledValue × 10^(-scale)。
假设有一个BigDecimal表示的数值是123.45,那么无标度值(Unscaled Value)是12345。标度(Scale)是2。因为123.45 = 12345 × 10^(-2)。
涉及到的字段就是这几个:
1 | public class BigDecimal extends Number implements Comparable<BigDecimal> { |
关于无标度值的压缩机制大家了解即可,不是本文的重点,大家只需要知道BigDecimal主要是通过一个无标度值和标度来表示的就行了。
那么标度到底是什么呢?
除了scale这个字段,在BigDecimal中还提供了scale()方法,用来返回这个BigDecimal的标度。
1 | /** |
那么,scale到底表示的是什么,其实上面的注释已经说的很清楚了。
当标度为正数时,它表示小数点后的位数。例如,在数字123.45中,他的无标度值为12345,标度是2。
当标度为零时,BigDecimal表示一个整数。
当标度为负数时,它表示小数点向左移动的位数,相当于将数字乘以 10 的绝对值的次方。例如,一个数值为1234500,那么他可以用value是12345,scale为-2来表示,因为1234500 * 10^(-2) = 12345。(当需要处理非常大的整数时,可以使用负数的标度来指定小数点左侧的位数。这在需要保持整数的精度而又不想丢失尾部零位时很有用。)
而二进制无法表示的0.1,使用BigDecimal就可以表示了,及通过无标度值1和标度1来表示。
我们都知道,想要创建一个对象,需要使用该类的构造方法,在BigDecimal中一共有以下4个构造方法:
1 | BigDecimal(int) |
以上四个方法,创建出来的BigDecimal的标度(scale)是不同的。
其中 BigDecimal(int)和BigDecimal(long) 比较简单,因为都是整数,所以他们的标度都是0。
而BigDecimal(double) 和BigDecimal(String)的标度就有很多学问了。
BigDecimal(double)有什么问题
BigDecimal中提供了一个通过double创建BigDecimal的方法——BigDecimal(double) ,但是,同时也给我们留了一个坑!
因为我们知道,double表示的小数是不精确的,如0.1这个数字,double只能表示他的近似值。
所以,当我们使用new BigDecimal(0.1)创建一个BigDecimal 的时候,其实创建出来的值并不是正好等于0.1的。
而是0.1000000000000000055511151231257827021181583404541015625。这是因为double自身表示的只是一个近似值。
所以,如果我们在代码中,使用BigDecimal(double) 来创建一个BigDecimal的话,那么是损失了精度的,这是极其严重的。
使用BigDecimal(String)创建
那么,该如何创建一个精确的BigDecimal来表示小数呢,答案是使用String创建。
而对于BigDecimal(String) ,当我们使用new BigDecimal(“0.1”)创建一个BigDecimal 的时候,其实创建出来的值正好就是等于0.1的。
那么他的标度也就是1。
但是需要注意的是,new BigDecimal(“0.10000”)和new BigDecimal(“0.1”)这两个数的标度分别是5和1,如果使用BigDecimal的equals方法比较,得到的结果是false。
那么,想要创建一个能精确的表示0.1的BigDecimal,请使用以下两种方式:
1 | BigDecimal recommend1 = new BigDecimal("0.1"); |
这里,留一个思考题,BigDecimal.valueOf()是调用Double.toString方法实现的,那么,既然double都是不精确的,BigDecimal.valueOf(0.1)怎么保证精确呢?
总结
因为计算机采用二进制处理数据,但是很多小数,如0.1的二进制是一个无限循环小数,而这种数字在计算机中是无法精确表示的。
所以,人们采用了一种通过近似值的方式在计算机中表示,于是就有了单精度浮点数和双精度浮点数等。
所以,作为单精度浮点数的float和双精度浮点数的double,在表示小数的时候只是近似值,并不是真实值。
所以,当使用BigDecimal(Double)创建一个的时候,得到的BigDecimal是损失了精度的。
而使用一个损失了精度的数字进行计算,得到的结果也是不精确的。
想要避免这个问题,可以通过BigDecimal(String)的方式创建BigDecimal,这样的情况下,0.1就会被精确的表示出来。
其表现形式是一个无标度数值1,和一个标度1的组合。
✅BigDecimal和Long表示金额哪个更合适,怎么选择?
典型回答
大家都知道,不能用Float和Double来表示金额,会存在丢失精度的问题。
那么要表示金额,业内有两种做法:
1、单位为分,数据库存bigint,代码中用long
2、单位为元,数据库用decimal,代码中用BigDecimal(我们一般数据库存储的是decimal(18,6))
这两种,其实我们都用过,而且现在也还都在用,因为他们都有各自的优缺点以及适用场景。
首先说BigDecimal,BigDecimal 是 Java 中用于精确计算的类,特别适合于需要高精度数值计算的场景,如金融、计量和工程等领域。其特点如下:
- 精确度高:
BigDecimal可以表示非常大或非常精确的小数,而不会出现浮点数那样的舍入误差。 - 灵活的数学运算:它提供各种方法进行精确的算术操作,包括加减乘除和四舍五入等。
- 控制舍入行为:在进行数学运算时,你可以指定舍入模式,这对于金融计算非常重要。
所以,BigDecimal的适用场景是需要高精度计算的金融应用,如货币计算、利率计算等。比如我们的结算系统、支付系统、账单系统等,都是用BigDecimal的。
其次,再说Long,long 是 Java 的一种基本数据类型,用于表示没有小数部分的整数。其特点如下:
- 性能高:作为基本数据类型,
long在处理速度上比BigDecimal快很多。 - 容量限制:
long可以表示的最大值为 (2^{63}-1),最小值为 (-2^{63})。这在大多数应用程序中已经足够,但在表示非常大的数或需要小数的计算中则不适用。 - 不适合精确的小数运算:
long无法处理小数,如果需要代表金额中的小数部分(如厘),则需要自行管理这一部分。
所以,Long的适用场景是适合于不涉及小数计算的大整数运算,如某些计数应用或者金额以整数形式表示。比如我们的额度系统、积分系统等。
很多人会有疑惑,什么情况下会出现需要比分还小的单位呢?其实就是在很多需要运算的场景,比如说金融的费率、利率、服务费的费率等等,这些都是很小的,一般都是万分之几或者千分之几。而一旦有一个单位为元的金额和一个”率”相乘的时候,就会出现小于分的单位。
那有人说,遇到分我就直接四舍五入不就行了么,反正结算也是按照分结算的。这样做会有问题,我举个例子。
我一笔账单,有两笔订单,金额都是1元,存储的时候按照分存储,即100分,然后我的服务费费率是0.004。
如果是以分为单位,long存储和表示的话,那么两笔订单分开算费率的话:100*0.004 = 0.4 ,四舍五入 0, 两笔加在一起,收入的费率就是0分。
但是如说是以元为单位,bigdecimal存储和表示的话,那么两笔订单分开算费率的话:1*0.004 = 0.004 , 两笔加在一起0.008,当我要结算的时候,再做四舍五入就是0.01元,即1分钱。
所以,因为long在计算和存储的过程中都会丢失掉小数部分,那就会导致每一次都被迫需要四舍五入。而decimal完全可以保留过程中的数据,再最终需要的时候做一次整体的四舍五入,这样结果就会更加精确!
所以,如果你的应用需要处理小数点后的精确计算(如金融计算中常见的多位小数),则应选择 BigDecimal。
如果你的应用对性能要求极高,并且没有乘除类运算,不需要很小的精度时,那么使用 long 可能更合适。
总结来说,对于绝大多数涉及货币计算的应用,推荐使用 BigDecimal,因为它提供了必要的精度和灵活性,尽管牺牲了一些性能。如果确定不需要处理小数,并且对执行速度有极端要求,使用 long 可能更适合。
✅char能存储中文吗?
典型回答
在Java中,char类型是用来表示一个16位(2个字节)的Unicode字符,它可以存储任何Unicode字符集中的字符,当然也包括中文字符。
例如:
1 | char ch = '龗'; |
但是,有人说,Java中的char是没办法表示生僻字的,这么说其实有点绝对了。
因为Unicode字符集包含了几乎所有的字符,包括常见字符、生僻字、罕见字以及其他语言的字符。所以,用char类型其实是可以存储生僻字的。
但是,在处理生僻字时,需要确保Java源代码文件本身以及编译器和运行时环境都支持Unicode字符集。另外,如果在字符串中使用生僻字,也需要注意字符编码和字符串长度的问题。
还有一点需要注意,Unicode字符集的目标是覆盖世界上所有的字符。然而,由于生僻字的数量庞大且不断增长,Unicode字符集可能无法及时收录所有生僻字。这主要取决于Unicode标准的版本以及生僻字的使用频率和普及程度。
虽然Unicode字符集也在一直不断的迭代更新,但是对于一些非常罕见的生僻字,它们可能因为版本问题,或者时间问题,暂时不在Unicode字符集中。在这种情况下,可能就会无法表示。
✅ClassNotFoundException和NoClassDefFoundError的区别是什么?
典型回答
ClassNotFoundException是一个受检异常(checked exception)。他通常在运行时,在类加载阶段尝试加载类的过程中,找不到类的定义时触发。通常是由Class.forName()或类加载器loadClass或者findSystemClass时,在类路径中没有找到指定名称的类时,会抛出该异常。表示所需的类在类路径中不存在。这通常是由于类名拼写错误或缺少依赖导致的。
如以下方式加载JDBC驱动:
1 | public class MainClass |
当我们的classpath中没有对应的jar包时,就会抛出这个ClassNotFoundException。
NoClassDefFoundError是一个错误(error),它表示运行时尝试加载一个类的定义时,虽然找到了类文件,但在加载、解析或链接类的过程中发生了问题。这通常是由于依赖问题或类定义文件(.class文件)损坏导致的。也就是说这个类在编译时存在,运行时丢失了,就会导致这个异常。
如以下情况,我们定义A类和B类,
1 | class A |
在编译后会生成A.class和B.class,当我们删除A.class之后,单独运行B.class的时候,就会发生NoClassDefFoundError
扩展知识
NoSuchMethodError
NoSuchMethodError表示方法找不到,他和NoClassDefFoundError类似,都是编译期找得到,运行期找不到了。
这种error发生在生产环境中是,通常来说大概率是发生了jar包冲突。
✅final、finally、finalize有什么区别
典型回答
final、finally、finalize有什么区别?这个问题就像周杰、周杰伦和周星驰之间有啥关系的问题一样。其实没啥关系,放在一起比较无非是名字有点像罢了。
final、finally和finalize是Java中的三个不同的概念。
- final:用于声明变量、方法或类,使之不可变、不可重写或不可继承。
- finally:是异常处理的一部分,用于确保代码块(通常用于资源清理)总是执行。
- finalize:是Object类的一个方法,用于在对象被垃圾回收前执行清理操作,但通常不推荐使用。
final
final是一个关键字,可以用来修饰变量、方法和类。分别代表着不同的含义。
final变量:即我们所说的常量,一旦被赋值后,就不能被修改。
1 | final int x = 100; |
final方法:不能被子类重写。
1 | public final void show() { |
final类:不能被继承。
1 | public final class MyFinalClass { |
finally
finally是一个用于异常处理,它和try、catch块一起使用。无论是否捕获或处理异常,finally块中的代码总是执行(程序正常执行的情况)。通常用于关闭资源,如输入/输出流、数据库连接等。
1 | try { |
finalize
finalize是Object类的一个方法,用于垃圾收集过程中的资源回收。在对象被垃圾收集器回收之前,finalize方法会被调用,用于执行清理操作(例如释放资源)。但是,不推荐依赖finalize方法进行资源清理,因为它的调用时机不确定且不可靠。
1 | protected void finalize() throws Throwable { |
✅finally中代码一定会执行吗?
典型回答
通常情况下,finally的代码一定会被执行,但是这是有一个前提的,:
1、对应 try 语句块被执行,
2、程序正常运行。
如果没有符合这两个条件的话,finally中的代码就无法被执行,如发生以下情况,都会导致finally不会执行:
1、System.exit()方法被执行
2、Runtime.getRuntime().halt()方法被执行
3、try或者catch中有死循环
4、操作系统强制杀掉了JVM进程,如执行了kill -9
5、其他原因导致的虚拟机崩溃了
6、虚拟机所运行的环境挂了,如计算机电源断了
7、如果一个finally是由守护线程执行的,那么是不保证一定能执行的,如果这时候JVM要退出,JVM会检查其他非守护线程,如果都执行完了,那么就直接退出了。这时候finally可能就没办法执行完。
✅Java的动态代理如何实现?
典型回答
在Java中,实现动态代理有两种方式:
- JDK动态代理:Java.lang.reflect 包中的Proxy类和InvocationHandler接口提供了生成动态代理类的能力。
- Cglib动态代理:Cglib (Code Generation Library )是一个第三方代码生成类库,运行时在内存中动态生成一个子类对象从而实现对目标对象功能的扩展。
JDK动态代理和Cglib动态代理的区别:
JDK的动态代理有一个限制,就是使用动态代理的对象必须实现一个或多个接口。如果想代理没有实现接口的类,就可以使用CGLIB实现。
Cglib是一个强大的高性能的代码生成包,它可以在运行期扩展Java类与实现Java接口。它广泛的被许多AOP的框架使用,例如Spring AOP和dynaop,为他们提供方法的interception(拦截)。
Cglib包的底层是通过使用一个小而快的字节码处理框架ASM,来转换字节码并生成新的类。不鼓励直接使用ASM,因为它需要你对JVM内部结构包括class文件的格式和指令集都很熟悉。
所以,使用JDK动态代理的对象必须实现一个或多个接口;而使用cglib代理的对象则无需实现接口,达到代理类无侵入。
拓展知识
静态代理和动态代理的区别
最大的区别就是静态代理是编译期确定的,但是动态代理却是运行期确定的。
同时,使用静态代理模式需要程序员手写很多代码,这个过程是比较浪费时间和精力的。一旦需要代理的类中方法比较多,或者需要同时代理多个对象的时候,这无疑会增加很大的复杂度。
反射是动态代理的实现方式之一。
动态代理的用途
Java的动态代理,在日常开发中可能并不经常使用,但是并不代表他不重要。Java的动态代理的最主要的用途就是应用在各种框架中。因为使用动态代理可以很方便的运行期生成代理类,通过代理类可以做很多事情,比如AOP,比如过滤器、拦截器等。
在我们平时使用的框架中,像servlet的filter、包括spring提供的aop以及struts2的拦截器都使用了动态代理功能。我们日常看到的mybatis分页插件,以及日志拦截、事务拦截、权限拦截这些几乎全部由动态代理的身影。
Spring AOP的实现方式
Spring AOP中的动态代理主要有两种方式,JDK动态代理和CGLIB动态代理。
JDK动态代理通过反射来接收被代理的类,并且要求被代理的类必须实现一个接口。JDK动态代理的核心是InvocationHandler接口和Proxy类。
如果目标类没有实现接口,那么Spring AOP会选择使用CGLIB来动态代理目标类。
CGLIB(Code Generation Library),是一个代码生成的类库,可以在运行时动态的生成某个类的子类,注意,CGLIB是通过继承的方式做的动态代理,因此如果某个类被标记为final,那么它是无法使用CGLIB做动态代理的。
JDK 动态代理的代码段
1 | public class UserServiceImpl implements UserService { |
Cglib动态代理的代码段
1 | public class UserServiceImpl implements UserService { |
✅Java和C++主要区别有哪些?各有哪些优缺点?
典型回答
Java和C++都是面向对象的语言,他们一个是编译型语言,一个是解释型语言。
C++是编译型语言(首先将源代码编译生成机器码,再由机器运行机器码),执行速度快、效率高;依赖编译器、跨平台性差些。
Java是解释型语言(源代码不是直接翻译成机器语言,而是先翻译成中间代码,再由解释器对中间代码进行解释运行。),执行速度慢、效率低;依赖解释器、跨平台性好。
PS:也有人说Java是半编译、半解释型语言。Java 编译器(javac)先将java源程序编译成Java字节码(.class),JVM负责解释执行字节码文件。
二者更多的主要区别如下:
| Java | C++ | |
|---|---|---|
| 跨平台 | 平台无关 | 平台有关 |
| 内存管理 | 自动 | 手动 |
| 参数传递方式 | 值传递 | 引用、指针、值传递 |
| 多继承 | 不支持 | 支持 |
| 系统资源的控制能力 | 弱 | 强 |
| 适合领域 | 企业级Web应用开发 | 系统编程、游戏开发等 |
C++是平台相关的,Java是平台无关的。
Java是自动内存管理和垃圾回收的,C++需要手动内存管理,支持析构函数,Java没有析构函数的概念。
C++支持指针,引用,传值调用 。Java只有值传递。
C++支持多重继承,包括虚拟继承 。Java只允许单继承,需要多继承的情况要使用接口。
C++对所有的数字类型有标准的范围限制,但字节长度是跟具体实现相关的,同一个类型在不同操作系统可能长度不一样。Java在所有平台上对所有的基本类型都有标准的范围限制和字节长度。
C++除了一些比较少见的情况之外和C语言兼容 。 Java没有对任何之前的语言向前兼容。但在语法上受 C/C++ 的影响很大
C++允许直接调用本地的系统库 。 Java要通过JNI调用。
Java的优点是跨平台能力强,支持自动内存管理减少内存泄露风险。有大量的库和框架支持(特别是企业级应用开发),并且还有较强的社区支持和资源。
Java的缺点是性能不如C++,对系统资源的控制能力较弱。
C++的优点是性能高,控制能力强。可以直接操作内存和硬件的能力。适用于系统编程、游戏开发、实时系统。同时也有丰富的库和工具,特别是在图形和游戏领域。
C++的缺点是内存管理复杂,容易出错。跨平台开发困难。代码会比较复杂,学习曲线比较陡。
✅Java是值传递还是引用传递?
典型回答
编程语言中需要进行方法间的参数传递,这个传递的策略叫做求值策略。
在程序设计中,求值策略有很多种,比较常见的就是值传递和引用传递。
值传递和引用传递最大的区别是传递的过程中有没有复制出一个副本来,如果是传递副本,那就是值传递,否则就是引用传递。
Java对象的传递,是通过复制的方式把引用关系传递了,因为有复制的过程,所以是值传递,只不过对于Java对象的传递,传递的内容是对象的引用。
扩展知识
Java的求值策略
前面我们介绍过了传值调用、传引用调用以及传值调用的特例传共享对象调用,那么,Java中是采用的哪种求值策略呢?
很多人说Java中的基本数据类型是值传递的,这个基本没有什么可以讨论的,普遍都是这样认为的。
但是,有很多人却误认为Java中的对象传递是引用传递。之所以会有这个误区,主要是因为Java中的变量和对象之间是有引用关系的。Java语言中是通过对象的引用来操纵对象的。所以,很多人会认为对象的传递是引用的传递。
而且很多人还可以举出以下的代码示例:
1 | public static void main(String[] args) { |
输出结果:
1 | print in pass , user is User{name='hollischuang', gender='Male'} |
可以看到,对象类型在被传递到pass方法后,在方法内改变了其内容,最终调用方main方法中的对象也变了。
所以,很多人说,这和引用传递的现象是一样的,就是在方法内改变参数的值,会影响到调用方。
但是,其实这是走进了一个误区。
Java中的对象传递
很多人通过代码示例的现象说明Java对象是引用传递,那么我们就从现象入手,先来反驳下这个观点。
我们前面说过,无论是值传递,还是引用传递,只不过是求值策略的一种,那求值策略还有很多,比如前面提到的共享对象传递的现象和引用传递也是一样的。那凭什么就说Java中的参数传递就一定是引用传递而不是共享对象传递呢?
那么,Java中的对象传递,到底是哪种形式呢?其实,还真的就是共享对象传递。
其实在 《The Java™ Tutorials》中,是有关于这部分内容的说明的。首先是关于基本类型描述如下:
Primitive arguments, such as an int or a double, are passed into methods by value. This means that any changes to the values of the parameters exist only within the scope of the method. When the method returns, the parameters are gone and any changes to them are lost.
即,原始参数通过值传递给方法。这意味着对参数值的任何更改都只存在于方法的范围内。当方法返回时,参数将消失,对它们的任何更改都将丢失。
关于对象传递的描述如下:
Reference data type parameters, such as objects, are also passed into methods by value. This means that when the method returns, the passed-in reference still references the same object as before. However, the values of the object’s fields can be changed in the method, if they have the proper access level.
也就是说,引用数据类型参数(如对象)也按值传递给方法。这意味着,当方法返回时,传入的引用仍然引用与以前相同的对象。但是,如果对象字段具有适当的访问级别,则可以在方法中更改这些字段的值。
这一点官方文档已经很明确的指出了,Java就是值传递,只不过是把对象的引用当做值传递给方法。你细品,这不就是共享对象传递么?
**其实Java中使用的求值策略就是传共享对象调用,也就是说,Java会将对象的地址的拷贝传递给被调函数的形式参数。**只不过”传共享对象调用”这个词并不常用,所以Java社区的人通常说”Java是传值调用”,这么说也没错,因为传共享对象调用其实是传值调用的一个特例。
值传递和共享对象传递的现象冲突吗?
看到这里很多人可能会有一个疑问,既然共享对象传递是值传递的一个特例,那么为什么他们的现象是完全不同的呢?
难道值传递过程中,如果在被调方法中改变了值,也有可能会对调用者有影响吗?那到底什么时候会影响什么时候不会影响呢?
其实是不冲突的,之所以会有这种疑惑,是因为大家对于到底是什么是”改变值”有误解。
我们先回到上面的例子中来,看一下调用过程中实际上发生了什么?
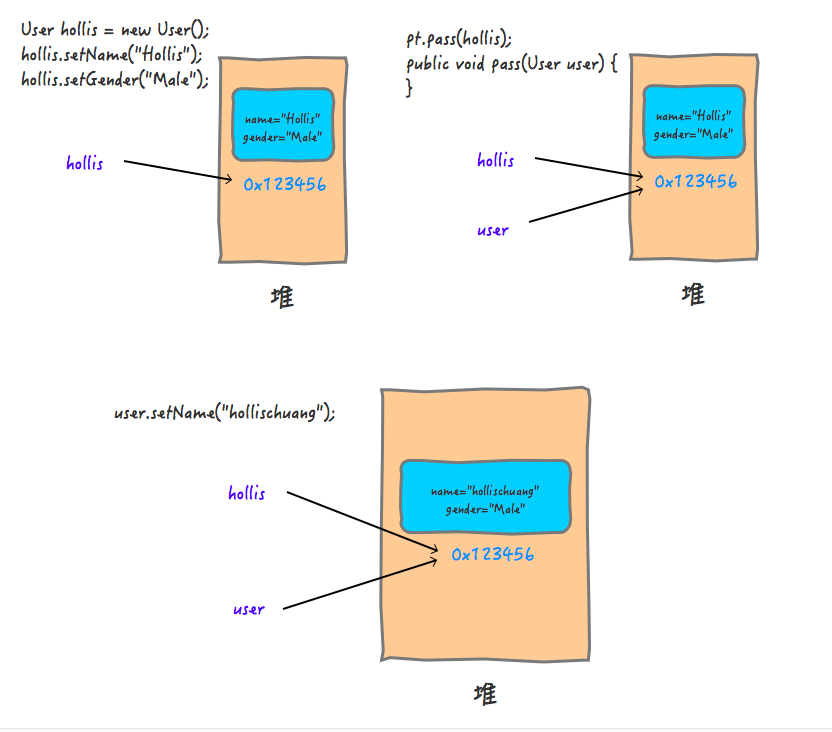
在参数传递的过程中,实际参数的地址0X1213456被拷贝给了形参。这个过程其实就是值传递,只不过传递的值得内容是对象的引用。
那为什么我们改了user中的属性的值,却对原来的user产生了影响呢?
其实,这个过程就好像是:你复制了一把你家里的钥匙给到你的朋友,他拿到钥匙以后,并没有在这把钥匙上做任何改动,而是通过钥匙打开了你家里的房门,进到屋里,把你家的电视给砸了。
这个过程,对你手里的钥匙来说,是没有影响的,但是你的钥匙对应的房子里面的内容却是被人改动了。
也就是说,Java对象的传递,是通过复制的方式把引用关系传递了,如果我们没有改引用关系,而是找到引用的地址,把里面的内容改了,是会对调用方有影响的,因为大家指向的是同一个共享对象。
那么,如果我们改动一下pass方法的内容:
1 | public void pass(User user) { |
上面的代码中,我们在pass方法中,重新new了一个user对象,并改变了他的值,输出结果如下:
1 | print in pass , user is User{name='hollischuang', gender='Male'} |
再看一下整个过程中发生了什么:
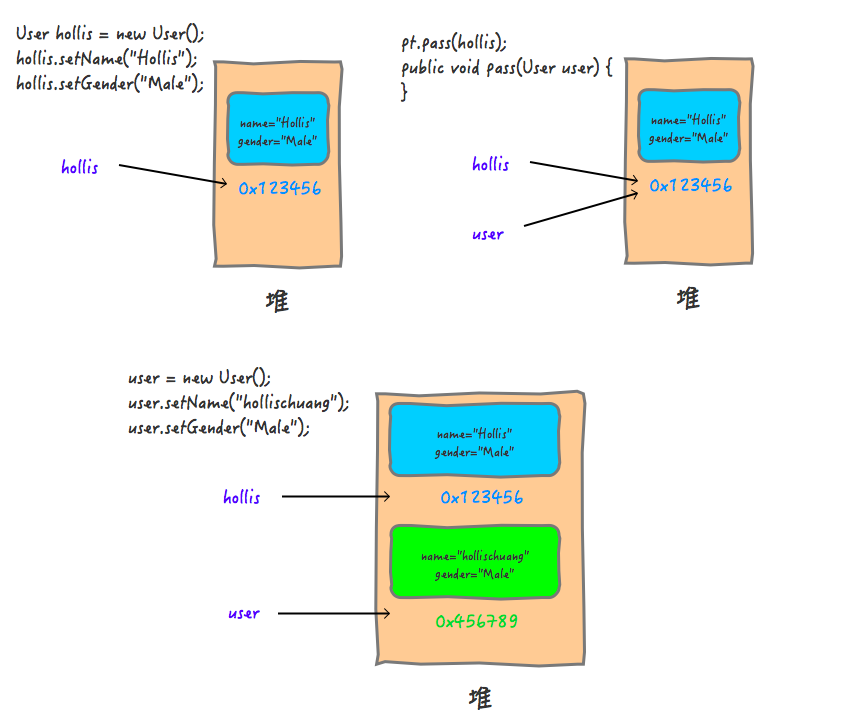
这个过程,就好像你复制了一把钥匙给到你的朋友,你的朋友拿到你给他的钥匙之后,找个锁匠把他修改了一下,他手里的那把钥匙变成了开他家锁的钥匙。这时候,他打开自己家,就算是把房子点了,对你手里的钥匙,和你家的房子来说都是没有任何影响的。
所以,Java中的对象传递,如果是修改引用,是不会对原来的对象有任何影响的,但是如果直接修改共享对象的属性的值,是会对原来的对象有影响的。
总结
我们知道,编程语言中需要进行方法间的参数传递,这个传递的策略叫做求值策略。
在程序设计中,求值策略有很多种,比较常见的就是值传递和引用传递。还有一种值传递的特例——共享对象传递。
值传递和引用传递最大的区别是传递的过程中有没有复制出一个副本来,如果是传递副本,那就是值传递,否则就是引用传递。
在Java中,其实是通过值传递实现的参数传递,只不过对于Java对象的传递,传递的内容是对象的引用。
我们可以总结说,Java中的求值策略是共享对象传递,这是完全正确的。
但是,为了让大家都能理解你说的,我们说Java中只有值传递,只不过传递的内容是对象的引用。这也是没毛病的。
但是,绝对不能认为Java中有引用传递。
OK,以上就是本文的全部内容,不知道本文是否帮助你解开了你心中一直以来的疑惑。欢迎留言说一下你的想法。
✅Java序列化的原理是啥
典型回答
序列化是将对象转换为可传输格式的过程。 是一种数据的持久化手段。一般广泛应用于网络传输,RMI和RPC等场景中。 几乎所有的商用编程语言都有序列化的能力,不管是数据存储到硬盘,还是通过网络的微服务传输,都需要序列化能力。
在Java的序列化机制中,如果是String,枚举或者实现了Serializable接口的类,均可以通过Java的序列化机制,将类序列化为符合编码的数据流,然后通过InputStream和OutputStream将内存中的类持久化到硬盘或者网络中;同时,也可以通过反序列化机制将磁盘中的字节码再转换成内存中的类。
**如果一个类想被序列化,需要实现Serializable接口。**否则将抛出NotSerializableException异常。Serializable接口没有方法或字段,仅用于标识可序列化的语义。
自定义类通过实现Serializable接口做标识,进而在IO中实现序列化和反序列化,具体的执行路径如下:
#writeObject -> #writeObject0(判断类是否是自定义类) -> #writeOrdinaryObject(区分Serializable和Externalizable) -> writeSerialData(序列化fields) -> invokeWriteObject(反射调用类自己的序列化策略)
其中,在invokeWriteObject的阶段,系统就会处理自定义类的序列化方案。
这是因为,在序列化操作过程中会对类型进行检查,要求被序列化的类必须属于Enum、Array和Serializable类型其中的任何一种。
知识拓展
Serializable 和 Externalizable 接口有何不同?
类通过实现 java.io.Serializable 接口以启用其序列化功能。未实现此接口的类将无法使其任何状态序列化或反序列化。可序列化类的所有子类型本身都是可序列化的。序列化接口没有方法或字段,仅用于标识可序列化的语义。
当试图对一个对象进行序列化的时候,如果遇到不支持 Serializable 接口的对象。在此情况下,将抛出 NotSerializableException。
如果要序列化的类有父类,要想同时将在父类中定义过的变量持久化下来,那么父类也应该实现java.io.Serializable接口。
Externalizable继承了Serializable,该接口中定义了两个抽象方法:writeExternal()与readExternal()。当使用Externalizable接口来进行序列化与反序列化的时候需要开发人员重写writeExternal()与readExternal()方法。如果没有在这两个方法中定义序列化实现细节,那么序列化之后,对象内容为空。实现Externalizable接口的类必须要提供一个public的无参的构造器。
所以,实现Externalizable,并实现writeExternal()和readExternal()方法可以指定序列化哪些属性。
在Java中,有哪些好的序列化框架,有什么好处
Java中常用的序列化框架:
java、kryo、hessian、protostuff、gson、fastjson等。
Kryo:速度快,序列化后体积小;跨语言支持较复杂
Hessian:默认支持跨语言;效率不高
Protostuff:速度快,基于protobuf;需静态编译
Protostuff-Runtime:无需静态编译,但序列化前需预先传入schema;不支持无默认构造函数的类,反序列化时需用户自己初始化序列化后的对象,其只负责将该对象进行赋值
Java:使用方便,可序列化所有类;速度慢,占空间
✅Java中Timer实现定时调度的原理是什么?
典型回答
Java中的Timer类是一个定时调度器,用于在指定的时间点执行任务。JDK 中Timer类的定义如下:
1 | public class Timer { |
以上就是Timer中最重要的两个成员变量:
- TaskQueue:一个任务队列,用于存储已计划的定时任务。任务队列按照任务的执行时间进行排序,确保最早执行的任务排在队列前面。在队列中的任务可能是一次性的,也可能是周期性的。
- TimerThread:Timer 内部的后台线程,它负责扫描 TaskQueue 中的任务,检查任务的执行时间,然后在执行时间到达时执行任务的 run() 方法。TimerThread 是一个守护线程,因此当所有非守护线程完成时,它会随之终止。
任务的定时调度的核心代码就在TimerThread中:
1 | class TimerThread extends Thread { |
可以看到,TimerThread的实际是在运行mainLoop方法,这个方法一进来就是一个while(true)的循环,他在循环中不断地从TaskQueue中取出第一个任务,然后判断他是否到达执行时间了,如果到了,就触发任务执行。否则就继续等一会再次执行。
不断地重复这个动作,从队列中取出第一个任务进行判断,执行。。。
这样只要有新的任务加入队列,就在队列中按照时间排序,然后唤醒timerThread重新检查队列进行执行就可以了。代码如下:
1 | private void sched(TimerTask task, long time, long period) { |
扩展知识
优缺点
Timer 类用于实现定时任务,最大的好处就是他的实现非常简单,特别的轻量级,因为它是Java内置的,所以只需要简单调用就行了。
但是他并不是特别的解决定时任务的好的方案,因为他存在以下问题:
1、Timer内部是单线程执行任务的,如果某个任务执行时间较长,会影响后续任务的执行。
2、如果任务抛出未捕获异常,将导致整个 Timer 线程终止,影响其他任务的执行。
3、Timer 无法提供高精度的定时任务。因为系统调度和任务执行时间的不确定性,可能导致任务执行的时间不准确。
4、虽然可以使用 cancel 方法取消任务,但这仅仅是将任务标记为取消状态,仍然会在任务队列中占用位置,无法释放资源。这可能导致内存泄漏。
5、当有大量任务时,Timer 的性能可能受到影响,因为它在每次扫描任务队列时都要进行时间比较。
6、Timer执行任务完全基于JVM内存,一旦应用重启,那么队列中的任务就都没有了
✅Java中创建对象有哪些种方式
典型回答
使用new关键字
这是我们最常见的也是最简单的创建对象的方式,通过这种方式我们还可以调用任意的构造函数(无参的和有参的)。
User user = new User();
使用反射机制
运用反射手段,调用Java.lang.Class或者java.lang.reflect.Constructor类的newInstance()实例方法。
1 使用Class类的newInstance方法
可以使用Class类的newInstance方法创建对象。这个newInstance方法调用无参的构造函数创建对象。
1 | User user = (User)Class.forName("xxx.xxx.User").newInstance(); |
2 使用Constructor类的newInstance方法
和Class类的newInstance方法很像, java.lang.reflect.Constructor类里也有一个newInstance方法可以创建对象。我们可以通过这个newInstance方法调用有参数的和私有的构造函数。
1 | Constructor constructor = User.class.getConstructor(); |
这两种newInstance方法就是大家所说的反射。事实上Class的newInstance方法内部调用Constructor的newInstance方法。
使用clone方法
无论何时我们调用一个对象的clone方法,jvm就会创建一个新的对象,将前面对象的内容全部拷贝进去。用clone方法创建对象并不会调用任何构造函数。
要使用clone方法,我们需要先实现Cloneable接口并实现其定义的clone方法。如果只实现了Cloneable接口,并没有重写clone方法的话,会默认使用Object类中的clone方法,这是一个native的方法。
1 | public class CloneTest implements Cloneable{ |
使用反序列化
当我们序列化和反序列化一个对象,jvm会给我们创建一个单独的对象。其实反序列化也是基于反射实现的。
1 | public static void main(String[] args) { |
使用方法句柄
通过使用方法句柄,可以间接地调用构造函数来创建对象
1 |
|
使用了MethodHandles.lookup().findConstructor()方法获取构造函数的方法句柄,然后通过invoke()方法调用构造函数来创建对象。
使用Unsafe分配内存
在Java中,可以使用sun.misc.Unsafe类来进行直接的内存操作,包括内存分配和对象实例化。然而,需要注意的是,sun.misc.Unsafe类是Java的内部API,它并不属于Java标准库的一部分,也不建议直接在生产环境中使用。
1 |
|
这种方式有以下几个缺点:
- 不可移植性:Unsafe类的行为在不同的Java版本和不同的JVM实现中可能会有差异,因此代码在不同的环境下可能会出现不可移植的问题。
- 安全性问题:Unsafe类的功能是非常强大和危险的,可以绕过Java的安全机制,可能会导致内存泄漏、非法访问、数据损坏等安全问题。
- 不符合面向对象的原则:Java是一门面向对象的语言,鼓励使用构造函数和工厂方法来创建对象,以确保对象的正确初始化和维护对象的不变性。
✅Java中的static都能用来修饰什么?
典型回答
在Java编程语言中,static关键字是非常重要的修饰符,可以用于多种不同的地方。可用来修饰变量、方法、代码块以及类。
- ** 静态变量**:
- 定义:静态变量属于类本身,而不是类的任何特定实例(new出来的对象)。
- 特点:
- 所有实例共享同一静态变量。
- 在类加载到内存时就被初始化,而不是在创建对象的时候。
- 常用于管理类的全局状态或作为常量仓库(例如
public static final修饰的常量)。
1 | public class Counter { |
- 静态方法:
- 定义:静态方法同样属于类,而非类的实例。
- 特点:
- 可以在不创建类的实例的情况下调用。
- 不能访问类的实例变量或实例方法,它们只能访问其他的静态成员。
- 常用于工具类的方法,例如
Math.sqrt()或Collections.sort()。
1 | public class MathUtils { |
- ** 静态代码块**:
- 定义:用于初始化类的静态变量。
- 特点:
- 当类被Java虚拟机加载并初始化时执行。
- 通常用于执行静态变量的复杂初始化。
1 | public class DatabaseConfig { |
- 静态内部类:
- 定义:在一个类的内部定义的静态类。
- 特点:
- 可以不依赖于外部类的实例而独立存在。
- 可以访问外部类的所有静态成员,但不能直接访问外部类的实例成员。
- 常用于当内部类的行为不应依赖于外部类的实例时。
1 | public class OuterClass { |
使用static修饰符的好处包括减少内存使用(共享静态变量而不是为每个实例创建副本)、提供一个全局访问点(例如静态方法和变量)以及无需实例化类即可使用其中的方法和变量。
✅Java中的枚举有什么特点和好处
枚举类型是指由一组固定的常量组成合法的类型。Java中由关键字enum来定义一个枚举类型
1 | public enum Season { |
Java中枚举的好处如下:
1、枚举的valueOf可以自动对入参进行非法参数的校验
Java 枚举提供了 valueOf 方法,它可以根据字符串值返回相应的枚举常量。如果传入的字符串不匹配任何枚举常量,valueOf 会抛出 IllegalArgumentException 异常,从而自动进行非法参数的校验。
1 | public class EnumExample { |
2、可以调用枚举中的方法,相对于普通的常量来说操作性更强
枚举可以定义方法,这使得每个枚举常量都可以具备独特的行为。与普通常量相比,枚举更具操作性和灵活性。
1 | public enum Operation { |
3、枚举实现接口的话,可以很容易的实现策略模式
4、枚举可以自带属性,扩展性更强
枚举可以包含字段、构造函数和方法,使得每个枚举常量可以具有不同的属性和行为。
1 | public enum Color { |
5、天生就是个单例,线程安全且不怕被破坏
扩展知识
枚举如何实现的?
如果我们使用反编译,对一个枚举进行反编译的话,就能大致了解他的实现方式,如上面的Season枚举,反编译后内容如下:
1 | public final class T extends Enum |
通过反编译后代码我们可以看到,public final class T extends Enum,说明,该类是继承了Enum类的,同时final关键字告诉我们,这个类也是不能被继承的。当我们使用enum来定义一个枚举类型的时候,编译器会自动帮我们创建一个final类型的类继承Enum类,所以枚举类型不能被继承,我们看到这个类中有几个属性和方法。
枚举如何比较
枚举的equals方法底层用的还是==,所以两者都可以
✅Java中异常分哪两类,有什么区别?
典型回答
Java中的异常,主要可以分为两大类,即受检异常(checked exception)和 非受检异常(unchecked exception)
对于受检异常来说,如果一个方法在声明的过程中证明了其要有受检异常抛出:
public void test() throws Exception{}
那么,当我们在程序中调用他的时候,一定要对该异常进行处理(捕获或者向上抛出),否则是无法编译通过的。这是一种强制规范。
这种异常在IO操作中比较多。比如FileNotFoundException ,当我们使用IO流处理一个文件的时候,有一种特殊情况,就是文件不存在,所以,在文件处理的接口定义时他会显示抛出FileNotFoundException,起目的就是告诉这个方法的调用者,我这个方法不保证一定可以成功,是有可能找不到对应的文件的,你要明确的对这种情况做特殊处理哦。
所以说,当我们希望我们的方法调用者,明确的处理一些特殊情况的时候,就应该使用受检异常。
对于非受检异常来说,一般是运行时异常,继承自RuntimeException。在编写代码的时候,不需要显式的捕获,但是如果不捕获,在运行期如果发生异常就会中断程序的执行。
这种异常一般可以理解为是代码原因导致的。比如发生空指针、数组越界等。所以,只要代码写的没问题,这些异常都是可以避免的。也就不需要我们显示的进行处理。
试想一下,如果你要对所有可能发生空指针的地方做异常处理的话,那相当于你的所有代码都需要做这件事。
知识扩展
什么是Throwable
Throwable是java中最顶级的异常类,继承Object,实现了序列化接口,有两个重要的子类:Exception和 Error,二者都是 Java 异常处理的重要子类,各自都包含大量子类。
Error和Exception的区别和联系
error表示系统级的错误,是java运行环境内部错误或者硬件问题,不能指望程序来处理这样的问题,除了退出运行外别无选择,它是Java虚拟机抛出的。如OutOfMemoryError、StackOverflowError
✅Java中有了基本类型为什么还需要包装类?
典型回答
Java中有8种基本数据类型,这些基本类型又都有对应的包装类。
| 分类 | 基本数据类型 | 包装类 | 长度 | 表示范围 |
|---|---|---|---|---|
| 布尔型 | boolean | Boolean | / | / |
| 整型 | byte | Byte | 1字节 | -128 到 127 |
| short | Short | 2字节 | -32,768 到 32,767 | |
| int | Integer | 4字节 | -2,147,483,648 到 2,147,483,647 | |
| long | Long | 8字节 | -9,223,372,036,854,775,808 到 9,223,372,036,854,775,807 | |
| 字符型 | char | Character | 2字节 | Unicode字符集中的任何字符 |
| 浮点型 | float | Float | 4字节 | 约 -3.4E38 到 3.4E38 |
| double | Double | 8字节 | 约 -1.7E308 到 1.7E308 |
因为Java是一种面向对象语言,很多地方都需要使用对象而不是基本数据类型。比如,在集合类中,我们是无法将int 、double等类型放进去的。因为集合的容器要求元素是Object类型。
为了让基本类型也具有对象的特征,就出现了包装类型,它相当于将基本类型“包装起来”,使得它具有了对象的性质,并且为其添加了属性和方法,丰富了基本类型的操作。
知识扩展
基本类型和包装类型的区别
- 默认值不同,基本类型的默认值为0, false或\u0000等,包装类默认为null
- 初始化方式不同,一个需要new,一个不需要
- 存储方式不同,基本类型保存在栈上,包装类对象保存在堆上(成员变量的话,在不考虑JIT优化的栈上分配时,都是随着对象一起保存在堆上的)
接口定义中应该用什么?
如何理解自动拆装箱
拆箱与装箱
“>包装类是对基本类型的包装,所以,把基本数据类型转换成包装类的过程就是**”>装箱**”>;反之,把包装类转换成基本数据类型的过程就是**”>拆箱**”>。
自动拆装箱
“>在Java SE5中,为了减少开发人员的工作,Java提供了自动拆箱与自动装箱功能。
“>
“>自动装箱: 就是将基本数据类型自动转换成对应的包装类。
“>
“>自动拆箱:就是将包装类自动转换成对应的基本数据类型。
1 | Integer i =10; //自动装箱 |
自动拆装箱原理
自动装箱都是通过包装类的valueOf()方法来实现的.自动拆箱都是通过包装类对象的xxxValue()来实现的。
如:int的自动装箱都是通过Integer.valueOf()方法来实现的,Integer的自动拆箱都是通过Integer.intValue()来实现的。
哪些地方会自动拆装箱
我们了解过原理之后,再来看一下,什么情况下,Java会帮我们进行自动拆装箱。前面提到的变量的初始化和赋值的场景就不介绍了,那是最简单的也最容易理解的。
我们主要来看一下,那些可能被忽略的场景。
场景一、将基本数据类型放入集合类
我们知道,Java中的集合类只能接收对象类型,那么以下代码为什么会不报错呢?
1 | List<Integer> li = new ArrayList<>(); |
将上面代码进行反编译,可以得到以下代码:
1 | List<Integer> li = new ArrayList<>(); |
以上,我们可以得出结论,当我们把基本数据类型放入集合类中的时候,会进行自动装箱。
场景二、包装类型和基本类型的大小比较
有没有人想过,当我们对Integer对象与基本类型进行大小比较的时候,实际上比较的是什么内容呢?看以下代码:
1 | Integer a=1; |
对以上代码进行反编译,得到以下代码:
1 | Integer a=1; |
可以看到,包装类与基本数据类型进行比较运算,是先将包装类进行拆箱成基本数据类型,然后进行比较的。
场景三、包装类型的运算
有没有人想过,当我们对Integer对象进行四则运算的时候,是如何进行的呢?看以下代码:
1 | Integer i = 10; |
反编译后代码如下:
1 | Integer i = Integer.valueOf(10); |
我们发现,两个包装类型之间的运算,会被自动拆箱成基本类型进行。
场景四、三目运算符的使用
这是很多人不知道的一个场景,作者也是一次线上的血淋淋的Bug发生后才了解到的一种案例。看一个简单的三目运算符的代码:
1 | boolean flag = true; //设置成true,保证条件表达式的表达式二一定可以执行 |
很多人不知道,其实在int k = flag ? i : j;这一行,会发生自动拆箱。反编译后代码如下:
1 | boolean flag = true; |
这其实是三目运算符的语法规范。当第二,第三位操作数分别为基本类型和对象时,其中的对象就会拆箱为基本类型进行操作。
可以看到,反编译后的代码的最后一行,编译器帮我们做了一次自动拆箱,而就是因为这次自动拆箱,导致代码出现对于一个null对象(nullBoolean.booleanValue())的调用,导致了NPE。
场景五、函数参数与返回值
这个比较容易理解,直接上代码了:
1 | //自动拆箱 |
自动拆装箱与缓存
Java SE的自动拆装箱还提供了一个和缓存有关的功能,我们先来看以下代码,猜测一下输出结果:
1 | public static void main(String... strings) { |
我们普遍认为上面的两个判断的结果都是false。虽然比较的值是相等的,但是由于比较的是对象,而对象的引用不一样,所以会认为两个if判断都是false的。在Java中,==比较的是对象引用,而equals比较的是值。所以,在这个例子中,不同的对象有不同的引用,所以在进行比较的时候都将返回false。奇怪的是,这里两个类似的if条件判断返回不同的布尔值。
上面这段代码真正的输出结果:
1 | integer1 == integer2 |
原因就和Integer中的缓存机制有关。在Java 5中,在Integer的操作上引入了一个新功能来节省内存和提高性能。整型对象通过使用相同的对象引用实现了缓存和重用。
适用于整数值区间-128 至 +127。
只适用于自动装箱。使用构造函数创建对象不适用。
我们只需要知道,当需要进行自动装箱时,如果数字在-128至127之间时,会直接使用缓存中的对象,而不是重新创建一个对象。
其中的javadoc详细的说明了缓存支持-128到127之间的自动装箱过程。最大值127可以通过-XX:AutoBoxCacheMax=size修改。
实际上这个功能在Java 5中引入的时候,范围是固定的-128 至 +127。后来在Java 6中,可以通过java.lang.Integer.IntegerCache.high设置最大值。
这使我们可以根据应用程序的实际情况灵活地调整来提高性能。到底是什么原因选择这个-128到127范围呢?因为这个范围的数字是最被广泛使用的。 在程序中,第一次使用Integer的时候也需要一定的额外时间来初始化这个缓存。
在Boxing Conversion部分的Java语言规范(JLS)规定如下:
如果一个变量p的值是:
1 | -128至127之间的整数(§3.10.1) |
范围内的时,将p包装成a和b两个对象时,可以直接使用a==b判断a和b的值是否相等。
✅Java注解的作用是啥
典型回答
Java 注解用于为 Java 代码提供元数据。作为元数据,注解不直接影响你的代码执行,但也有一些类型的注解实际上可以用于这一目的。Java 注解是从 Java5 开始添加到 Java 的。
Java的注解,可以说是一种标识,标识一个类或者一个字段,常常是和反射,AOP结合起来使用。中间件一般会定义注解,如果某些类或字段符合条件,就执行某些能力。
扩展知识
什么是元注解
说简单点,就是 定义其他注解的注解 。
比如Override这个注解,就不是一个元注解。而是通过元注解定义出来的。
1 |
|
这里面的@Target,@Retention就是元注解。
元注解有四个:@Target(表示该注解可以用于什么地方)、@Retention(表示在什么级别保存该注解信息)、@Documented(将此注解包含在javadoc中)、@Inherited(允许子类继承父类中的注解)。
一般@Target是被用的最多的。
@Retention
指定被修饰的注解的生命周期,即注解在源代码、编译时还是运行时保留。它有三个可选的枚举值:SOURCE、CLASS和RUNTIME。默认为CLASS。
1 | import java.lang.annotation.Retention; |
@Target
指定被修饰的注解可以应用于的元素类型,如类、方法、字段等。这样可以限制注解的使用范围,避免错误使用。
1 | import java.lang.annotation.Target; |
@Documented
用于指示注解是否会出现在生成的Java文档中。如果一个注解被@Documented元注解修饰,则该注解的信息会出现在API文档中,方便开发者查阅。
1 | import java.lang.annotation.Documented; |
@Inherited
指示被该注解修饰的注解是否可以被继承。默认情况下,注解不会被继承,即子类不会继承父类的注解。但如果将一个注解用@Inherited修饰,那么它就可以被子类继承。
1 | import java.lang.annotation.Inherited; |
✅JDK 9中对字符串的拼接做了什么优化?
典型回答
在JDK 9之前,字符串拼接通常使用+进行(也有其他的,我们不做展开了),+的实现其实是基于StringBuilder的。具体参考:
✅String、StringBuilder和StringBuffer的区别?
这个过程其实是比较低效的,因为整个过程包含了创建StringBuilder对象,通过调用append方法拼接字符串,最后通过toString方法转换成最终的字符串等多个操作。所以才有个规范说不要在 for 循环中用+来拼接字符串的。
但是,这个其实在 JDK 9中已经被修改了。JDK 9引入了StringConcatFactory。这玩意被推出的的主要目标是提供一种灵活且高效的方式来拼接字符串,代替之前的 StringBuilder 或 StringBuffer 的静态编译方法。
StringConcatFactory是基于invokedynamic指令实现的。
是 Java 7 中引入的一种动态类型指令,允许 JVM 在运行时动态解析和调用方法。
也就说,利用invokedynamic的特性,将字符串拼接的操作延迟到运行时,而不是在编译时固定使用StringBuilder。(前面的链接中我们做过反编译,可见+转成 StringBuilder是编译的时候就确定了的。)
这就使得,JVM可以在运行时根据实际的场景选择最优的拼接策略,可能是使用StringBuilder、StringBuffer、或者其他更高效的方法。
在 JDK 9中(后续版本会有所变化,1.9 看的比较清楚),支持的拼接策略有以下几个:
1 | private enum Strategy { |
StringBuilder你不陌生,MethodHandle 是啥?他 Java 7 开始引入的特性,它提供了一种灵活且高效的方法来直接操作方法、构造函数和字段的调用。
它与反射相似,但提供了更高的性能和更低的使用限制。MethodHandle 是一种非常底层的机制,允许开发者在运行时动态查找和调用方法,无论方法的访问权限如何。
使用 MethodHandles.lookup() 获取一个 Lookup 实例,然后使用这个实例来查找特定的方法。
1 | import java.lang.invoke.MethodHandle; |
使用 invoke, invokeExact, 或者其他形式的 invoke 方法来调用 MethodHandle。
✅JDK新版本中都有哪些新特性?
典型回答
JDK 8中推出了Lambda表达式、Stream、Optional、新的日期API等
JDK 9中推出了模块化
JDK 10中推出了本地变量类型推断
JDK 12中增加了switch表达式
JDK 13中增加了text block
JDK 14中增加了Records
JDK 14中增加了instance模式匹配
JDK 15中增加了封闭类
JDK 17中扩展了switch模式匹配
JDK 21中增加了协程
(以上没有把所有版本都列出是因为某些版本的特性并不重要,或者开发者不太需要关注)
扩展知识
本地变量类型推断
在Java 10之前版本中,我们想定义定义局部变量时。我们需要在赋值的左侧提供显式类型,并在赋值的右边提供实现类型:
1 | MyObject value = new MyObject(); |
在Java 10中,提供了本地变量类型推断的功能,可以通过var声明变量:
1 | var value = new MyObject(); |
本地变量类型推断将引入“var”关键字,而不需要显式的规范变量的类型。
其实,所谓的本地变量类型推断,也是Java 10提供给开发者的语法糖。
虽然我们在代码中使用var进行了定义,但是对于虚拟机来说他是不认识这个var的,在java文件编译成class文件的过程中,会进行解糖,使用变量真正的类型来替代var
Switch 表达式
在JDK 12中引入了Switch表达式作为预览特性。并在Java 13中修改了这个特性,引入了yield语句,用于返回值。
而在之后的Java 14中,这一功能正式作为标准功能提供出来。
在以前,我们想要在switch中返回内容,还是比较麻烦的,一般语法如下:
1 | int i; |
在JDK13中使用以下语法:
1 | int i = switch (x) { |
或者
1 | int i = switch (x) { |
在这之后,switch中就多了一个关键字用于跳出switch块了,那就是yield,他用于返回一个值。
和return的区别在于:return会直接跳出当前循环或者方法,而yield只会跳出当前switch块。
Text Blocks
Java 13中提供了一个Text Blocks的预览特性,并且在Java 14中提供了第二个版本的预览。
text block,文本块,是一个多行字符串文字,它避免了对大多数转义序列的需要,以可预测的方式自动格式化字符串,并在需要时让开发人员控制格式。
我们以前从外部copy一段文本串到Java中,会被自动转义,如有一段以下字符串:
1 | <html> |
将其复制到Java的字符串中,会展示成以下内容:
1 | "<html>\n" + |
即被自动进行了转义,这样的字符串看起来不是很直观,在JDK 13中,就可以使用以下语法了:
1 | """ |
使用"""作为文本块的开始符合结束符,在其中就可以放置多行的字符串,不需要进行任何转义。看起来就十分清爽了。
如常见的SQL语句:
1 | String query = """ |
看起来就比较直观,清爽了。
Records
Java 14 中便包含了一个新特性:EP 359: Records,
Records的目标是扩展Java语言语法,Records为声明类提供了一种紧凑的语法,用于创建一种类中是“字段,只是字段,除了字段什么都没有”的类。
通过对类做这样的声明,编译器可以通过自动创建所有方法并让所有字段参与hashCode()等方法。这是JDK 14中的一个预览特性。
使用record关键字可以定义一个记录:
1 | record Person (String firstName, String lastName) {} |
record 解决了使用类作为数据包装器的一个常见问题。纯数据类从几行代码显著地简化为一行代码。(详见:Java 14 发布了,不使用”class”也能定义类了?还顺手要干掉Lombok!)
封闭类
在Java 15之前,Java认为”代码重用”始终是一个终极目标,所以,一个类和接口都可以被任意的类实现或继承。
但是,在很多场景中,这样做是容易造成错误的,而且也不符合物理世界的真实规律。
例如,假设一个业务领域只适用于汽车和卡车,而不适用于摩托车。
在Java中创建Vehicle抽象类时,应该只允许Car和Truck类扩展它。
通过这种方式,我们希望确保在域内不会出现误用Vehicle抽象类的情况。
为了解决类似的问题,在Java 15中引入了一个新的特性——密闭。
想要定义一个密闭接口,可以将sealed修饰符应用到接口的声明中。然后,permit子句指定允许实现密闭接口的类:
1 | public sealed interface Service permits Car, Truck { |
以上代码定义了一个密闭接口Service,它规定只能被Car和Truck两个类实现。
与接口类似,我们可以通过使用相同的sealed修饰符来定义密闭类:
1 | public abstract sealed class Vehicle permits Car, Truck { |
通过密闭特性,我们定义出来的Vehicle类只能被Car和Truck继承。
instanceof 模式匹配
instanceof是Java中的一个关键字,我们在对类型做强制转换之前,会使用instanceof做一次判断,例如:
1 | if (animal instanceof Cat) { |
Java 14带来了改进版的instanceof操作符,这意味着我们可以用更简洁的方式写出之前的代码例子:
1 | if (animal instanceof Cat cat) { |
我们都不难发现这种写法大大简化了代码,省略了显式强制类型转换的过程,可读性也大大提高了。
switch 模式匹配
基于instanceof模式匹配这个特性,我们可以使用如下方式来对对象o进行处理:
1 | static String formatter(Object o) { |
可以看到,这里使用了很多if-else,其实,Java中给我们提供了一个多路比较的工具,那就是switch,而且从Java 14开始支持switch表达式,但switch的功能一直都是非常有限的。
在Java 17中,Java的工程师们扩展了switch语句和表达式,使其可以适用于任何类型,并允许case标签中不仅带有变量,还能带有模式匹配。我们就可以更清楚、更可靠地重写上述代码,例如:
1 | static String formatterPatternSwitch(Object o) { |
可以看到,以上的switch处理的是一个Object类型,而且case中也不再是精确的值匹配,而是模式匹配了。
✅Lambda表达式是如何实现的?
关于lambda表达式,有人可能会有质疑,因为网上有人说他并不是语法糖。其实我想纠正下这个说法。Labmda表达式不是匿名内部类的语法糖,但是他也是一个语法糖。实现方式其实是依赖了几个JVM底层提供的lambda相关api。
先来看一个简单的lambda表达式。遍历一个list:
1 | public static void main(String... args) { |
为啥说他并不是内部类的语法糖呢,前面讲内部类我们说过,内部类在编译之后会有两个class文件,但是,包含lambda表达式的类编译后只有一个文件。
反编译后代码如下:
1 | public static /* varargs */ void main(String ... args) { |
可以看到,在forEach方法中,其实是调用了java.lang.invoke.LambdaMetafactory#metafactory方法,该方法的第5个参数implMethod指定了方法实现。可以看到这里其实是调用了一个lambda$main$0方法进行了输出。
再来看一个稍微复杂一点的,先对List进行过滤,然后再输出:
1 | public static void main(String... args) { |
反编译后代码如下:
1 | public static /* varargs */ void main(String ... args) { |
两个lambda表达式分别调用了lambda$main$1和lambda$main$0两个方法。
所以,lambda表达式的实现其实是依赖了一些底层的api,在编译阶段,编译器会把lambda表达式进行解糖,转换成调用内部api的方式。
✅RPC接口返回中,使用基本类型还是包装类?
典型回答
使用包装类,不要使用基本类型,比如某个字段表示费率的Float rate,在接口中返回时,如果出现接口异常的情况,那么可能会返回默认值,float的话返回的是0.0,而Float返回的是null。
在接口中,为了避免发生歧义,建议使用对象,因为他默认值是null,当看到null的时候,我们明确的知道他是出错了,但是看到0.0的时候,你不知道是因为出错返回的0.0,还是就是不出错真的返回了0.0,虽然可以用其他的字段如错误码或者getSuccess判断,但是还是尽量减少歧义的可能
知识扩展
在接口定义的时候,如何定义一个字段表示是否成功?
以下四种:
1 | boolean success |
建议使用第2种:
1 | Boolean success |
首先,作为接口的返回对象的参数,这个字段不应该有不确定的值,而Boolean类型的默认值是null,而boolean的默认值是false,所以,当拿到一个false的时候,你就不知道是真的false了,还是因为出了问题而默认返回的false。
其他,关于参数名称,要使用success还是isSuccess,这一点在阿里巴巴Java开发手册中有明确规定和解释:
【强制】 POJO 类中的任何布尔类型的变量,都不要加 is,否则部分框架解析会引起序列化错误。
反例: 定义为基本数据类型 boolean isSuccess;的属性,它的方法也是 isSuccess(), RPC
框架在反向解析的时候, “ 以为” 对应的属性名称是 success,导致属性获取不到,进而抛出
异常。
✅serialVersionUID 有何用途? 如果没定义会有什么问题?
序列化是将对象的状态信息转换为可存储或传输的形式的过程。我们都知道,Java对象是保存在JVM的堆内存中的,也就是说,如果JVM堆不存在了,那么对象也就跟着消失了。
而序列化提供了一种方案,可以让你在即使JVM停机的情况下也能把对象保存下来的方案。就像我们平时用的U盘一样。
把Java对象序列化成可存储或传输的形式(如二进制流),比如保存在文件中。这样,当再次需要这个对象的时候,从文件中读取出二进制流,再从二进制流中反序列化出对象。
但是,虚拟机是否允许反序列化,不仅取决于类路径和功能代码是否一致,一个非常重要的一点是两个类的序列化 ID 是否一致,即serialVersionUID要求一致。
在进行反序列化时,JVM会把传来的字节流中的serialVersionUID与本地相应实体类的serialVersionUID进行比较,如果相同就认为是一致的,可以进行反序列化,否则就会出现序列化版本不一致的异常,即是InvalidCastException。这样做是为了保证安全,因为文件存储中的内容可能被篡改。
当实现java.io.Serializable接口的类没有显式地定义一个serialVersionUID变量时候,Java序列化机制会根据编译的Class自动生成一个serialVersionUID作序列化版本比较用,这种情况下,如果Class文件没有发生变化,就算再编译多次,serialVersionUID也不会变化的。但是,如果发生了变化,那么这个文件对应的serialVersionUID也就会发生变化。
基于以上原理,如果我们一个类实现了Serializable接口,但是没有定义serialVersionUID,然后序列化。在序列化之后,由于某些原因,我们对该类做了变更,重新启动应用后,我们相对之前序列化过的对象进行反序列化的话就会报错。
扩展知识
改了会怎么样
我们举个例子吧,看看如果serialVersionUID被修改了会发生什么?
1 | public class SerializableDemo1 { |
我们先执行以上代码,把一个User1对象写入到文件中。然后我们修改一下User1类,把serialVersionUID的值改为2L。
1 | class User1 implements Serializable { |
然后执行以下代码,把文件中的对象反序列化出来:
1 | public class SerializableDemo2 { |
执行结果如下:
1 | java.io.InvalidClassException: com.hollis.User1; local class incompatible: stream classdesc serialVersionUID = 1, local class serialVersionUID = 2 |
可以发现,以上代码抛出了一个java.io.InvalidClassException,并且指出serialVersionUID不一致。
这是因为,在进行反序列化时,JVM会把传来的字节流中的serialVersionUID与本地相应实体类的serialVersionUID进行比较,如果相同就认为是一致的,可以进行反序列化,否则就会出现序列化版本不一致的异常,即是InvalidClassException。
为什么要明确定一个serialVersionUID
如果我们没有在类中明确的定义一个serialVersionUID的话,看看会发生什么。
尝试修改上面的demo代码,先使用以下类定义一个对象,该类中不定义serialVersionUID,将其写入文件。
1 | class User1 implements Serializable { |
然后我们修改User1类,向其中增加一个属性。在尝试将其从文件中读取出来,并进行反序列化。
1 | class User1 implements Serializable { |
执行结果: java.io.InvalidClassException: com.hollis.User1; local class incompatible: stream classdesc serialVersionUID = -2986778152837257883, local class serialVersionUID = 7961728318907695402
同样,抛出了InvalidClassException,并且指出两个serialVersionUID不同,分别是-2986778152837257883和7961728318907695402。
从这里可以看出,系统自己添加了一个serialVersionUID。
所以,一旦类实现了Serializable,就建议明确的定义一个serialVersionUID。不然在修改类的时候,就会发生异常。
serialVersionUID有两种显示的生成方式:
一是默认的1L,比如:private static final long serialVersionUID = 1L;
二是根据类名、接口名、成员方法及属性等来生成一个64位的哈希字段,比如:
private static final long serialVersionUID = xxxxL;
✅SimpleDateFormat是线程安全的吗?使用时应该注意什么?
典型回答
在日常开发中,我们经常会用到时间,我们有很多办法在Java代码中获取时间。但是不同的方法获取到的时间的格式都不尽相同,这时候就需要一种格式化工具,把时间显示成我们需要的格式。
最常用的方法就是使用SimpleDateFormat类。这是一个看上去功能比较简单的类,但是,一旦使用不当也有可能导致很大的问题。
在阿里巴巴Java开发手册中,有如下明确规定:

也就是说SimpleDateFormat是非线程安全的,所以在多线程场景中,不能使用SimpleDateFormat作为共享变量。
因为SimpleDateFormat中的format方法在执行过程中,会使用一个成员变量calendar来保存时间。
如果我们在声明SimpleDateFormat的时候,使用的是static定义的。那么这个SimpleDateFormat就是一个共享变量,随之,SimpleDateFormat中的calendar也就可以被多个线程访问到。
假设线程1刚刚执行完calendar.setTime把时间设置成2018-11-11,还没等执行完,线程2又执行了calendar.setTime把时间改成了2018-12-12。这时候线程1继续往下执行,拿到的calendar.getTime得到的时间就是线程2改过之后的。
想要保证线程安全,要么就是不要把SDF设置成成员变量,只设置成局部变量就行了,要不然就是加锁避免并发,或者使用JDK 1.8中的DateTimeFormatter
扩展知识
SimpleDateFormat用法
SimpleDateFormat是Java提供的一个格式化和解析日期的工具类。它允许进行格式化(日期 -> 文本)、解析(文本 -> 日期)和规范化。SimpleDateFormat 使得可以选择任何用户定义的日期-时间格式的模式。
在Java中,可以使用SimpleDateFormat的format方法,将一个Date类型转化成String类型,并且可以指定输出格式。
1 | // Date转String |
以上代码,转换的结果是:2018-11-25 13:00:00,日期和时间格式由”日期和时间模式”字符串指定。如果你想要转换成其他格式,只要指定不同的时间模式就行了。
在Java中,可以使用SimpleDateFormat的parse方法,将一个String类型转化成Date类型。
1 | // String转Data |
日期和时间模式表达方法
在使用SimpleDateFormat的时候,需要通过字母来描述时间元素,并组装成想要的日期和时间模式。常用的时间元素和字母的对应表如下:
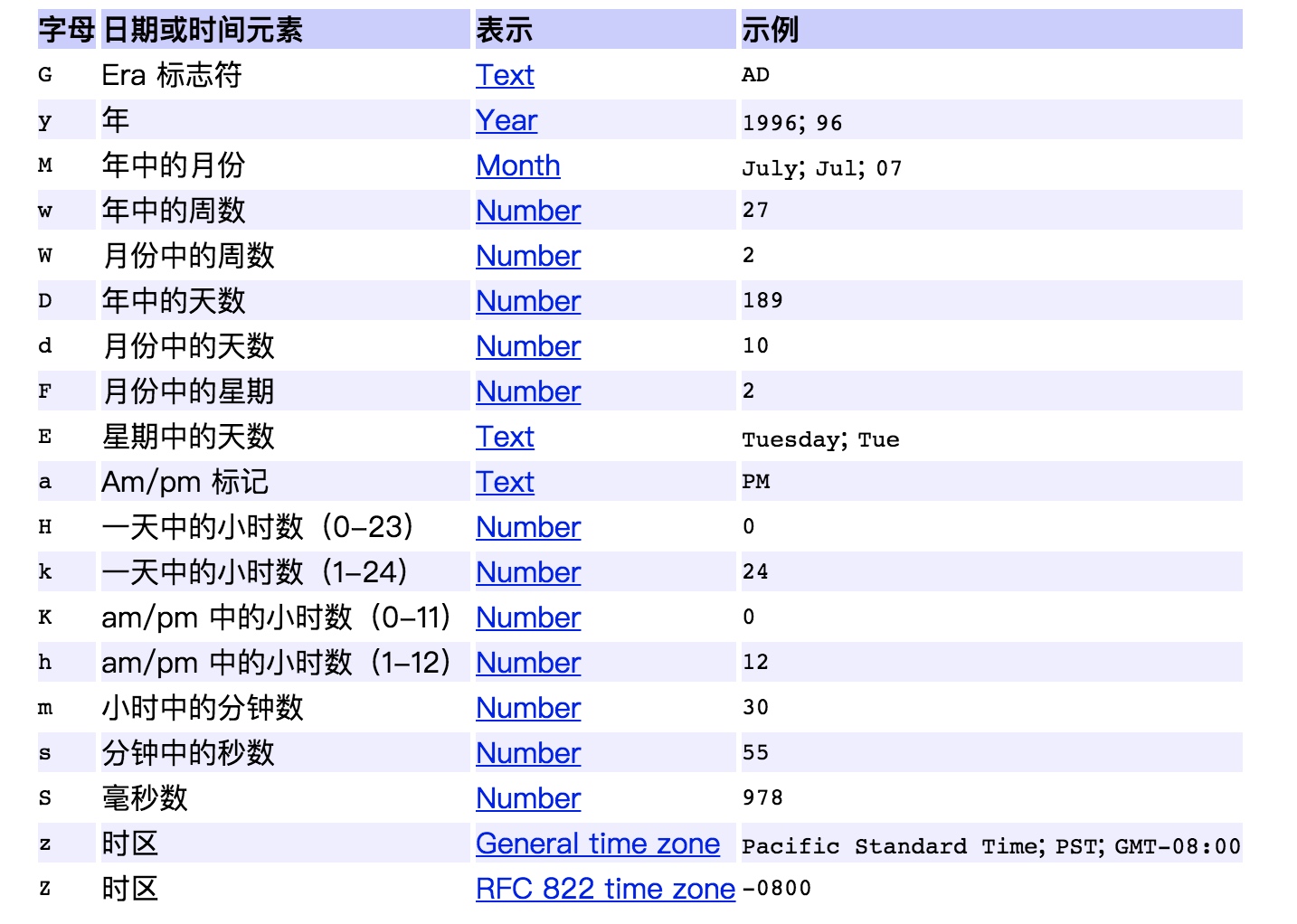
模式字母通常是重复的,其数量确定其精确表示。如下表是常用的输出格式的表示方法。

输出不同时区的时间
时区是地球上的区域使用同一个时间定义。以前,人们通过观察太阳的位置(时角)决定时间,这就使得不同经度的地方的时间有所不同(地方时)。1863年,首次使用时区的概念。时区通过设立一个区域的标准时间部分地解决了这个问题。
世界各个国家位于地球不同位置上,因此不同国家,特别是东西跨度大的国家日出、日落时间必定有所偏差。这些偏差就是所谓的时差。
现今全球共分为24个时区。由于使用上常常1个国家,或1个省份同时跨着2个或更多时区,为了照顾到行政上的方便,常将1个国家或1个省份划在一起。所以时区并不严格按南北直线来划分,而是按自然条件来划分。例如,中国幅员宽广,差不多跨5个时区,但为了使用方便简单,实际上在只用东八时区的标准时即北京时间为准。
由于不同的时区的时间是不一样的,甚至同一个国家的不同城市时间都可能不一样,所以,在Java中想要获取时间的时候,要重点关注一下时区问题。
默认情况下,如果不指明,在创建日期的时候,会使用当前计算机所在的时区作为默认时区,这也是为什么我们通过只要使用new Date()就可以获取中国的当前时间的原因。
那么,如何在Java代码中获取不同时区的时间呢?SimpleDateFormat可以实现这个功能。
1 | SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); |
以上代码,转换的结果是: 2018-11-24 21:00:00 。既中国的时间是11月25日的13点,而美国洛杉矶时间比中国北京时间慢了16个小时(这还和冬夏令时有关系,就不详细展开了)。
如果你感兴趣,你还可以尝试打印一下美国纽约时间(America/New_York)。纽约时间是2018-11-25 00:00:00。纽约时间比中国北京时间早了13个小时。
当然,这不是显示其他时区的唯一方法,不过本文主要为了介绍SimpleDateFormat,其他方法暂不介绍了。
SimpleDateFormat线程安全性
由于SimpleDateFormat比较常用,而且在一般情况下,一个应用中的时间显示模式都是一样的,所以很多人愿意使用如下方式定义SimpleDateFormat:
1 | public class Main { |
这种定义方式,存在很大的安全隐患。
问题重现
我们来看一段代码,以下代码使用线程池来执行时间输出。
1 | /** * @author Hollis */ |
以上代码,其实比较简单,很容易理解。就是循环一百次,每次循环的时候都在当前时间基础上增加一个天数(这个天数随着循环次数而变化),然后把所有日期放入一个线程安全的、带有去重功能的Set中,然后输出Set中元素个数。
上面的例子我特意写的稍微复杂了一些,不过我几乎都加了注释。这里面涉及到了线程池的创建、CountDownLatch、lambda表达式、线程安全的HashSet等知识。感兴趣的朋友可以逐一了解一下。
正常情况下,以上代码输出结果应该是100。但是实际执行结果是一个小于100的数字。
原因就是因为SimpleDateFormat作为一个非线程安全的类,被当做了共享变量在多个线程中进行使用,这就出现了线程安全问题。
在阿里巴巴Java开发手册的第一章第六节——并发处理中关于这一点也有明确说明:

那么,接下来我们就来看下到底是为什么,以及该如何解决。
线程不安全原因
通过以上代码,我们发现了在并发场景中使用SimpleDateFormat会有线程安全问题。其实,JDK文档中已经明确表明了SimpleDateFormat不应该用在多线程场景中:
Date formats are not synchronized. It is recommended to create separate format instances for each thread. If multiple threads access a format concurrently, it must be synchronized externally.
那么接下来分析下为什么会出现这种问题,SimpleDateFormat底层到底是怎么实现的?
我们跟一下SimpleDateFormat类中format方法的实现其实就能发现端倪。
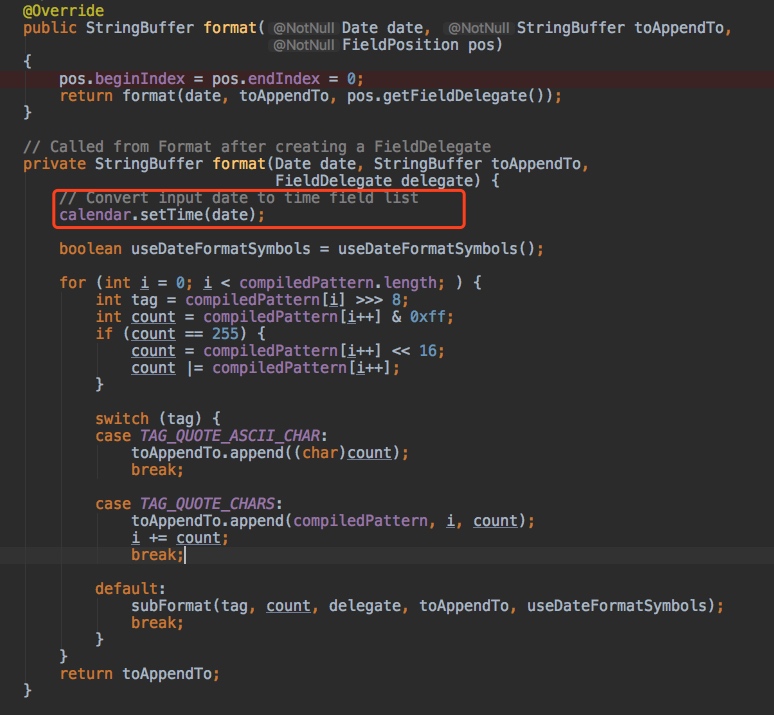
SimpleDateFormat中的format方法在执行过程中,会使用一个成员变量calendar来保存时间。这其实就是问题的关键。
由于我们在声明SimpleDateFormat的时候,使用的是static定义的。那么这个SimpleDateFormat就是一个共享变量,随之,SimpleDateFormat中的calendar也就可以被多个线程访问到。
假设线程1刚刚执行完calendar.setTime把时间设置成2018-11-11,还没等执行完,线程2又执行了calendar.setTime把时间改成了2018-12-12。这时候线程1继续往下执行,拿到的calendar.getTime得到的时间就是线程2改过之后的。
除了format方法以外,SimpleDateFormat的parse方法也有同样的问题。
所以,不要把SimpleDateFormat作为一个共享变量使用。
如何解决
前面介绍过了SimpleDateFormat存在的问题以及问题存在的原因,那么有什么办法解决这种问题呢?
解决方法有很多,这里介绍三个比较常用的方法。
使用局部变量
1 | for (int i = 0; i < 100; i++) { |
SimpleDateFormat变成了局部变量,就不会被多个线程同时访问到了,就避免了线程安全问题。
加同步锁
除了改成局部变量以外,还有一种方法大家可能比较熟悉的,就是对于共享变量进行加锁。
1 | for (int i = 0; i < 100; i++) { |
通过加锁,使多个线程排队顺序执行。避免了并发导致的线程安全问题。
其实以上代码还有可以改进的地方,就是可以把锁的粒度再设置的小一点,可以只对simpleDateFormat.format这一行加锁,这样效率更高一些。
使用ThreadLocal
第三种方式,就是使用 ThreadLocal。 ThreadLocal 可以确保每个线程都可以得到单独的一个 SimpleDateFormat 的对象,那么自然也就不存在竞争问题了。
1 | /** |
用 ThreadLocal 来实现其实是有点类似于缓存的思路,每个线程都有一个独享的对象,避免了频繁创建对象,也避免了多线程的竞争。
当然,以上代码也有改进空间,就是,其实SimpleDateFormat的创建过程可以改为延迟加载。这里就不详细介绍了。
使用DateTimeFormatter
如果是Java8应用,可以使用DateTimeFormatter代替SimpleDateFormat,这是一个线程安全的格式化工具类。就像官方文档中说的,这个类 simple beautiful strong immutable thread-safe。
1 | //解析日期 |
✅Stream的并行流一定比串行流更快吗?
典型回答
不一定!
Stream底层使用了ForkJoin进行并发处理,但是,并不代表着用了并发处理就一定比串行处理更快。有以下几个因素影响着并行流的性能:
线程管理的开销:并行流使用了多线程,而用了多线程就会带来线程管理和任务分配的开销。
任务分割:并行流的性能提升依赖于任务能够有效地分割和分配。如果任务分割不均衡,一些线程可能空闲或等待,从而影响性能。
线程争用:并行流使用公共的ForkJoinPool,如果系统中有其他并行任务,这些任务会争用线程资源,可能导致性能下降。
数据依赖性:并行流适用于没有数据依赖性的操作。如果操作之间存在依赖关系,并行流可能无法有效地提升性能,甚至可能导致错误。
环境配置:机器的硬件配置(例如CPU核心数)和当前系统负载也会影响并行流的性能。如果CPU核心数较少或负载较高,并行流的性能可能不如串行流。
在github(https://github.com/nickliuchao/stream/tree/master )上看到过有人做过测试,他测试的几个case是:
- 多核CPU服务器配置环境下,对比长度100的int数组的性能;
- 多核CPU服务器配置环境下,对比长度1.00E+8的int数组的性能;
- 多核CPU服务器配置环境下,对比长度1.00E+8对象数组过滤分组的性能;
- 单核CPU服务器配置环境下,对比长度1.00E+8对象数组过滤分组的性能。
主要区别就是CPU核数、任务的数量以及Stream中的元素的类型。得到的结果如下:
- 多核CPU服务器配置环境下,对比长度100的int数组
- 常规的迭代>Stream并行迭代>Stream串行迭代
- 多核CPU服务器配置环境下,对比长度1.00E+8的int数组
- Stream并行迭代>常规的迭代>Stream串行迭代
- 多核CPU服务器配置环境下,对比长度1.00E+8对象数组过滤分组
- Stream并行迭代>常规的迭代>Stream串行迭代
- 单核CPU服务器配置环境下,对比长度1.00E+8对象数组过滤分组
- 常规的迭代>Stream串行迭代>Stream并行迭代
所以,我们可以得到结论:
在单核CPU的情况下,Stream的串行迭代的效率是要高于Stream的并行迭代的效率的。
而在多核CPU的情况下,Stream的并行迭代速度要比Stream的串行迭代效率要高。但是,如果元素数量比较少的话,直接用常规迭代反而性能更好。
✅String、StringBuilder和StringBuffer的区别?
典型回答
String是不可变的,StringBuilder和StringBuffer是可变的。而StringBuffer是线程安全的,而StringBuilder是非线程安全的。
扩展知识
String的不可变性
为什么设计成不可变的
String的”+”是如何实现的
“>使用+”>拼接字符串,其实只是Java提供的一个语法糖, 那么,我们就来解一解这个语法糖,看看他的内部原理到底是如何实现的。
“>还是这样一段代码。我们把他生成的字节码进行反编译,看看结果。
1 | String wechat = "Hollis"; |
“>反编译后的内容如下,反编译工具为jad。
“>
1 | String wechat = "Hollis"; |
“>
“>通过查看反编译以后的代码,我们可以发现,原来字符串常量在拼接过程中,是将String转成了StringBuilder后,使用其append方法进行处理的。
“>
那么也就是说,Java中的+对字符串的拼接,其实现原理是使用StringBuilder.append。
StringBuffer和StringBuilder
接下来我们看看StringBuffer和StringBuilder的实现原理。
和String类类似,StringBuilder类也封装了一个字符数组,定义如下:
1 | char[] value; |
与String不同的是,它并不是final的,所以他是可以修改的。另外,与String不同,字符数组中不一定所有位置都已经被使用,它有一个实例变量,表示数组中已经使用的字符个数,定义如下:
1 | int count; |
其append源码如下:
1 | public StringBuilder append(String str) { |
该类继承了AbstractStringBuilder类,看下其append方法:
1 | public AbstractStringBuilder append(String str) { |
append会直接拷贝字符到内部的字符数组中,如果字符数组长度不够,会进行扩展。
StringBuffer和StringBuilder类似,最大的区别就是StringBuffer是线程安全的,看一下StringBuffer的append方法。
1 | public synchronized StringBuffer append(String str) { |
该方法使用synchronized进行声明,说明是一个线程安全的方法。而StringBuilder则不是线程安全的。
不要在for循环中使用+拼接字符串
前面我们分析过,其实使用+拼接字符串的实现原理也是使用的StringBuilder,那为什么不建议大家在for循环中使用呢?
1 | 我们把以下代码反编译下: |
反编译后代码如下(JDK 9之前 ):
1 | long t1 = System.currentTimeMillis(); |
我们可以看到,反编译后的代码,在for循环中,每次都是new了一个StringBuilder,然后再把String转成StringBuilder,再进行append。
而频繁的新建对象当然要耗费很多时间了,不仅仅会耗费时间,频繁的创建对象,还会造成内存资源的浪费。
所以,阿里巴巴Java开发手册建议:循环体内,字符串的连接方式,使用 StringBuilder 的 append 方法进行扩展。而不要使用+。
在JDK 9中,引入了StringConcatFactory对+进行了优化:
✅String a = “ab”; String b = “a” + “b”; a == b 吗?
典型回答
在Java中,对于字符串使用==比较的是字符串对象的引用地址是否相同。
因为”ab”和”a”、”b”都是由字面量(””包裹的内容)组成的字符串,在编译之后,会把用”+”拼接的字面量直接合在一起。因此他们的最终都是”ab”,而字面值最终在字符串池只有一份,所以a == b的结果为true,因为它们指向的是同一个字符串对象。
扩展知识
字面量
在计算机科学中,字面量(literal)是用于表达源代码中一个固定值的表示法(notation)。几乎所有计算机编程语言都具有对基本值的字面量表示,诸如:整数、浮点数以及字符串;而有很多也对布尔类型和字符类型的值也支持字面量表示;还有一些甚至对枚举类型的元素以及像数组、记录和对象等复合类型的值也支持字面量表示法。
以上是关于计算机科学中关于字面量的解释,并不是很容易理解。说简单点,字面量就是指由字母、数字等构成的字符串或者数值。
字面量只可以右值出现,所谓右值是指等号右边的值,如:int a=123这里的a为左值,123为右值。在这个例子中123就是字面量。
1 | int a = 123; |
上面的代码事例中,123和hollis都是字面量。
JVM为了提高性能和减少内存开销,在实例化字符串常量的时候进行了一些优化。为了减少在JVM中创建的字符串的数量,字符串类维护了一个字符串常量池。
在JVM中,有一块区域是运行时常量池,主要用来存储编译期生成的各种字面量和符号引用。
了解Class文件结构或者做过Java代码的反编译的朋友可能都知道,在java代码被javac编译之后,文件结构中是包含一部分Constant pool的。比如以下代码:
1 | public static void main(String[] args) { |
经过编译后,常量池内容如下:
1 | Constant pool: |
上面的Class文件中的常量池中,比较重要的几个内容:
1 | #16 = Utf8 s |
上面几个常量中,s就是前面提到的符号引用,而Hollis就是前面提到的字面量。
而Class文件中的常量池部分的内容,会在运行期被运行时常量池加载进去。
✅String str=new String(“hollis”)创建了几个对象?
典型回答
创建的对象数应该是1个或者2个。
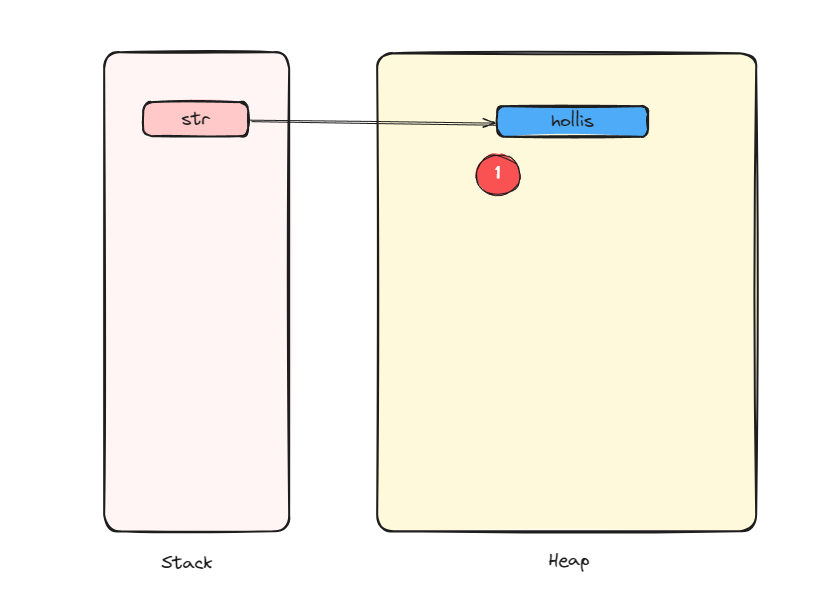
首先要清楚什么是对象?
Java是一种面向对象的语言,而Java对象在JVM中的存储也是有一定的结构的,在HotSpot虚拟机中,存储的形式就是oop-klass model,即Java对象模型。我们在Java代码中,使用new创建一个对象的时候,JVM会创建一个instanceOopDesc对象,这个对象中包含了两部分信息,对象头以及元数据。对象头中有一些运行时数据,其中就包括和多线程相关的锁的信息。元数据其实维护的是指针,指向的是对象所属的类的instanceKlass。
这才叫对象。其他的,一概都不叫对象。
那么不管怎么样,一次new的过程,都会在堆上创建一个对象,那么就是起码有一个对象了。至于另外一个对象,到底有没有要看具体情况了。
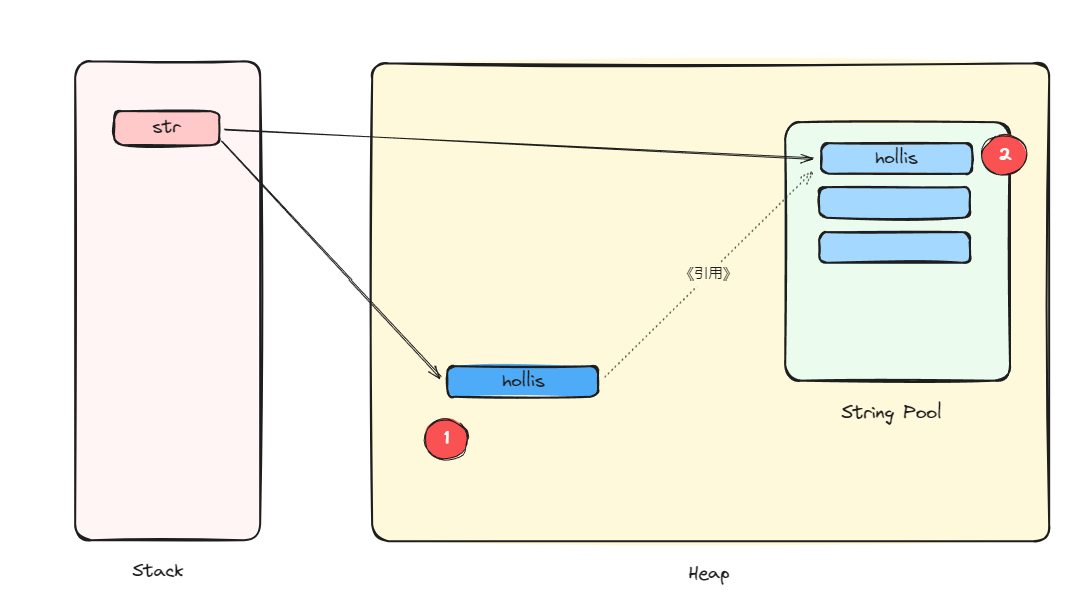
另外这一个对象就是常量池中的字符串常量,这个字符串其实是类编译阶段就进到Class常量池的,然后在运行期,字符串常量在第一次被调用(准确的说是ldc指令)的时候,进行解析并在字符串池中创建对应的String实例的。
在运行时常量池中,也并不是会立刻被解析成对象,而是会先以JVM_CONSTANT_UnresolveString_info的形式驻留在常量池。在后面,该引用第一次被LDC指令执行到的时候,就尝试在堆上创建字符串对象,并将对象的引用驻留在字符串常量池中。
通过看上面的过程,你也能发现,这个过程的触发条件是我们没办法决定的,问题的题干中也没提到。有可能执行这段代码的时候是第一次LDC指令执行,也许在前面就执行过了。
所以,如果是第一次执行,那么就是会同时创建两个对象。一个字符串常量引用指向的对象,一个我们new出来的对象。
如果不是第一次执行,那么就只会创建我们自己new出来的对象。
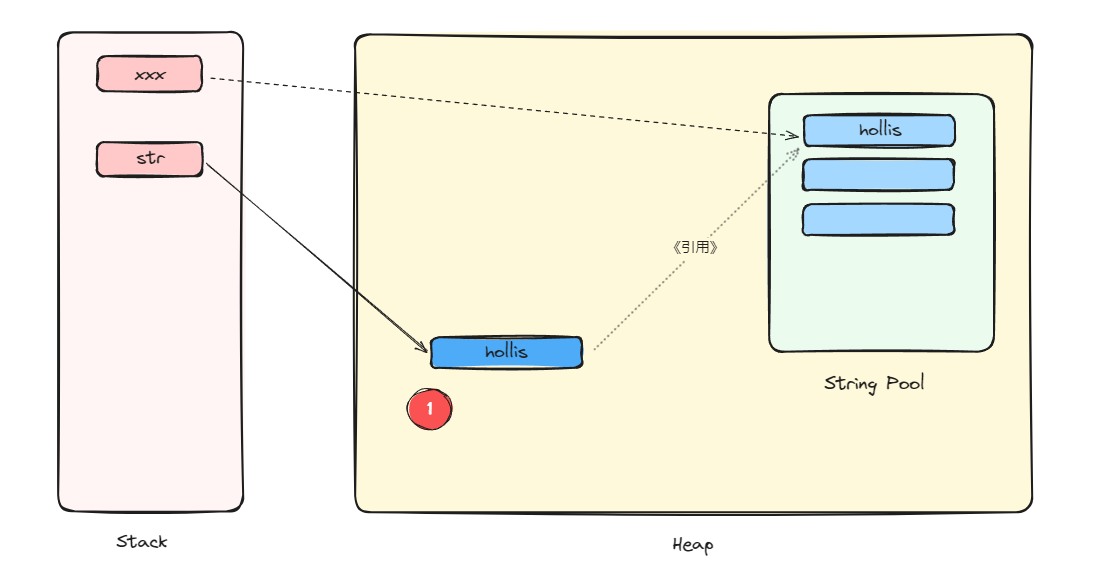
至于有人说什么在字符串池内还有在栈上还有一个引用对象,你听听这说法,引用就是引用。别往对象上面扯。
扩展知识
字面量和运行时常量池
JVM为了提高性能和减少内存开销,在实例化字符串常量的时候进行了一些优化。为了减少在JVM中创建的字符串的数量,字符串类维护了一个字符串常量池。
在JVM运行时区域的方法区中,有一块区域是运行时常量池,主要用来存储编译期生成的各种字面量和符号引用。
了解Class文件结构或者做过Java代码的反编译的朋友可能都知道,在java代码被javac编译之后,文件结构中是包含一部分Constant pool的。比如以下代码:
1 | public static void main(String[] args) { |
经过编译后,常量池内容如下:
1 | Constant pool: |
上面的Class文件中的常量池中,比较重要的几个内容:
1 | #16 = Utf8 s |
上面几个常量中,s就是前面提到的符号引用,而Hollis就是前面提到的字面量。而Class文件中的常量池部分的内容,会在运行期被运行时常量池加载进去。关于字面量,详情参考Java SE Specifications
intern
编译期生成的各种字面量和符号引用是运行时常量池中比较重要的一部分来源,但是并不是全部。那么还有一种情况,可以在运行期向运行时常量池中增加常量。那就是String的intern方法。
当一个String实例调用intern()方法时,Java查找常量池中是否有相同Unicode的字符串常量,如果有,则返回其的引用,如果没有,则在常量池中增加一个Unicode等于str的字符串并返回它的引用;
intern()有两个作用,第一个是将字符串字面量放入常量池(如果池没有的话),第二个是返回这个常量的引用。
intern的正确用法
不知道,你有没有发现,在String s3 = new String("Hollis").intern();中,其实intern是多余的?
因为就算不用intern,Hollis作为一个字面量也会被加载到Class文件的常量池,进而加入到运行时常量池中,为啥还要多此一举呢?到底什么场景下才需要使用intern呢?
在解释这个之前,我们先来看下以下代码:
1 | String s1 = "Hollis"; |
在经过反编译后,得到代码如下:
1 | String s1 = "Hollis"; |
可以发现,同样是字符串拼接,s3和s4在经过编译器编译后的实现方式并不一样。s3被转化成StringBuilder及append,而s4被直接拼接成新的字符串。
如果你感兴趣,你还能发现,String s3 = s1 + s2; 经过编译之后,常量池中是有两个字符串常量的分别是 Hollis、Chuang(其实Hollis和Chuang是String s1 = "Hollis";和String s2 = "Chuang";定义出来的),拼接结果HollisChuang并不在常量池中。
究其原因,是因为常量池要保存的是已确定的字面量值。也就是说,对于字符串的拼接,纯字面量和字面量的拼接,会把拼接结果作为常量保存到字符串池。
如果在字符串拼接中,有一个参数是非字面量,而是一个变量的话,整个拼接操作会被编译成StringBuilder.append,这种情况编译器是无法知道其确定值的。只有在运行期才能确定。
那么,有了这个特性了,intern就有用武之地了。那就是很多时候,我们在程序中得到的字符串是只有在运行期才能确定的,在编译期是无法确定的,那么也就没办法在编译期被加入到常量池中。
这时候,对于那种可能经常使用的字符串,使用intern进行定义,每次JVM运行到这段代码的时候,就会直接把常量池中该字面值的引用返回,这样就可以减少大量字符串对象的创建了。
如一深入解析String#intern文中举的一个例子:
1 | static final int MAX = 1000 * 10000; |
在以上代码中,我们明确的知道,会有很多重复的相同的字符串产生,但是这些字符串的值都是只有在运行期才能确定的。所以,只能我们通过intern显示的将其加入常量池,这样可以减少很多字符串的重复创建。
✅String是如何实现不可变的?
典型回答
我们都知道String是不可变的,但是它是怎么实现的呢?
先来看一段String的源码(JDK 1.8):
1 | public final class String |
以上代码,其实就包含了String不可变的主要实现了。
- String类被声明为final,这意味着它不能被继承。那么他里面的方法就是没办法被覆盖的。
- 用final修饰字符串内容的char[](从JDK 1.9开始,char[]变成了byte[]),由于该数组被声明为final,一旦数组被初始化,就不能再指向其他数组。
- String类没有提供用于修改字符串内容的公共方法。例如,没有提供用于追加、删除或修改字符的方法。如果需要对字符串进行修改,会创建一个新的String对象。
为什么JDK 9中把String的char[]改成了byte[]?
再然后,在他的一些方法中,如substring、concat等,在代码中如果有涉及到字符串的修改,也是通过new String()的方式新建了一个字符串。
所以,通过以上方式,使得一个字符串的内容,一旦被创建出来,就是不可以修改的了。
不可变对象是在完全创建后其内部状态保持不变的对象。这意味着,一旦对象被赋值给变量,我们既不能更新引用,也不能通过任何方式改变内部状态。
可是有人会有疑惑,String为什么不可变,我的代码中经常改变String的值啊,如下:
1 | String s = "abcd"; |
这样,操作,不就将原本的”abcd”的字符串改变成”abcdef”了么?
但是,虽然字符串内容看上去从”abcd”变成了”abcdef”,但是实际上,我们得到的已经是一个新的字符串了。
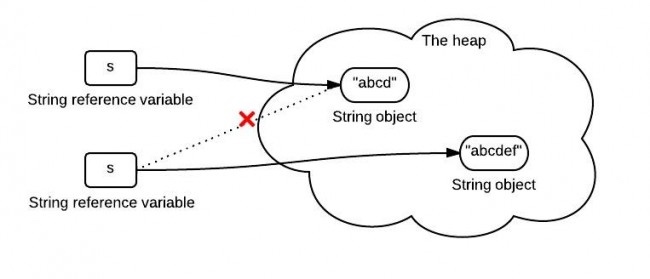
如上图,在堆中重新创建了一个”abcdef”字符串,和”abcd”并不是同一个对象。
所以,一旦一个string对象在内存(堆)中被创建出来,他就无法被修改。而且,String类的所有方法都没有改变字符串本身的值,都是返回了一个新的对象。
如果我们想要一个可修改的字符串,可以选择StringBuffer 或者 StringBuilder这两个代替String。
✅String为什么设计成不可变的?
为什么要把String设计成不可变的呢?有什么好处呢?
这个问题,困扰过很多人,甚至有人直接问过Java的创始人James Gosling。
在一次采访中James Gosling被问到什么时候应该使用不可变变量,他给出的回答是:
I would use an immutable whenever I can.
那么,他给出这个答案背后的原因是什么呢?是基于哪些思考的呢?
其实,主要是从缓存、安全性、线程安全和性能等角度出发的。
缓存
字符串是使用最广泛的数据结构。大量的字符串的创建是非常耗费资源的,所以,Java提供了对字符串的缓存功能,可以大大的节省堆空间。
JVM中专门开辟了一部分空间来存储Java字符串,那就是字符串池。
通过字符串池,两个内容相同的字符串变量,可以从池中指向同一个字符串对象,从而节省了关键的内存资源。
1 | String s = "abcd"; |
对于这个例子,s和s2都表示”abcd”,所以他们会指向字符串池中的同一个字符串对象:
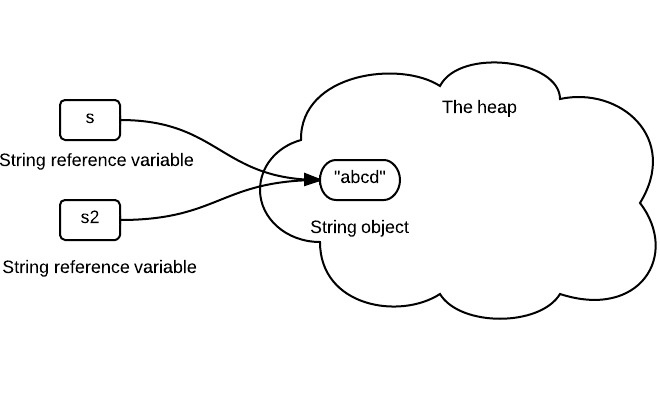
但是,之所以可以这么做,主要是因为字符串的不变性。试想一下,如果字符串是可变的,我们一旦修改了s的内容,那必然导致s2的内容也被动的改变了,这显然不是我们想看到的。
安全性
字符串在Java应用程序中广泛用于存储敏感信息,如用户名、密码、连接url、网络连接等。JVM类加载器在加载类的时也广泛地使用它。
因此,保护String类对于提升整个应用程序的安全性至关重要。
当我们在程序中传递一个字符串的时候,如果这个字符串的内容是不可变的,那么我们就可以相信这个字符串中的内容。
但是,如果是可变的,那么这个字符串内容就可能随时都被修改。那么这个字符串内容就完全不可信了。这样整个系统就没有安全性可言了。
线程安全
不可变会自动使字符串成为线程安全的,因为当从多个线程访问它们时,它们不会被更改。
因此,一般来说,不可变对象可以在同时运行的多个线程之间共享。它们也是线程安全的,因为如果线程更改了值,那么将在字符串池中创建一个新的字符串,而不是修改相同的值。因此,字符串对于多线程来说是安全的。
hashcode缓存
由于字符串对象被广泛地用作数据结构,它们也被广泛地用于哈希实现,如HashMap、HashTable、HashSet等。在对这些散列实现进行操作时,经常调用hashCode()方法。
不可变性保证了字符串的值不会改变。因此,hashCode()方法在String类中被重写,以方便缓存,这样在第一次hashCode()调用期间计算和缓存散列,并从那时起返回相同的值。
在String类中,有以下代码:
1 | private int hash;//this is used to cache hash code. |
性能
前面提到了的字符串池、hashcode缓存等,都是提升性能的体现。
因为字符串不可变,所以可以用字符串池缓存,可以大大节省堆内存。而且还可以提前对hashcode进行缓存,更加高效
由于字符串是应用最广泛的数据结构,提高字符串的性能对提高整个应用程序的总体性能有相当大的影响。
✅String有长度限制吗?是多少?
典型回答
有,编译期和运行期不一样。
编译期需要用CONSTANT_Utf8_info 结构用于表示字符串常量的值,而这个结构是有长度限制,他的限制是65535。
运行期,String的length参数是Int类型的,那么也就是说,String定义的时候,最大支持的长度就是int的最大范围值。根据Integer类的定义,java.lang.Integer#MAX_VALUE的最大值是2^31 - 1;
扩展知识
常量池限制
我们知道,javac是将Java文件编译成class文件的一个命令,那么在Class文件生成过程中,就需要遵守一定的格式。
根据《Java虚拟机规范》中第4.4章节常量池的定义,CONSTANT_String_info 用于表示 java.lang.String 类型的常量对象,格式如下:
1 | CONSTANT_String_info { |
其中,string_index 项的值必须是对常量池的有效索引, 常量池在该索引处的项必须是 CONSTANT_Utf8_info 结构,表示一组 Unicode 码点序列,这组 Unicode 码点序列最终会被初始化为一个 String 对象。
CONSTANT_Utf8_info 结构用于表示字符串常量的值:
1 | CONSTANT_Utf8_info { |
其中,length则指明了 bytes[]数组的长度,其类型为u2,
通过翻阅《规范》,我们可以获悉。u2表示两个字节的无符号数,那么1个字节有8位,2个字节就有16位。
16位无符号数可表示的最大值位2^16 - 1 = 65535。
也就是说,Class文件中常量池的格式规定了,其字符串常量的长度不能超过65535。
那么,我们尝试使用以下方式定义字符串:
1 | String s = "11111...1111";//其中有65535个字符"1" |
尝试使用javac编译,同样会得到”错误: 常量字符串过长”,那么原因是什么呢?
其实,这个原因在javac的代码中是可以找到的,在Gen类中有如下代码:
1 | private void checkStringConstant(DiagnosticPosition var1, Object var2) { |
代码中可以看出,当参数类型为String,并且长度大于等于65535的时候,就会导致编译失败。
这个地方大家可以尝试着debug一下javac的编译过程( 视频中有对java的编译过程进行debug的方法),也可以发现这个地方会报错。
如果我们尝试以65534个字符定义字符串,则会发现可以正常编译。
其实,关于这个值,在《Java虚拟机规范》也有过说明:
if the Java Virtual Machine code for a method is exactly 65535 bytes long and ends with an instruction that is 1 byte long, then that instruction cannot be protected by an exception handler. A compiler writer can work around this bug by limiting the maximum size of the generated Java Virtual Machine code for any method, instance initialization method, or static initializer (the size of any code array) to 65534 bytes
运行期限制
上面提到的这种String长度的限制是编译期的限制,也就是使用String s= “”;这种字面值方式定义的时候才会有的限制。
那么。String在运行期有没有限制呢,答案是有的。
String类中有很多重载的构造函数,其中有几个是支持用户传入length来执行长度的:
1 | public String(byte bytes[], int offset, int length) |
可以看到,这里面的参数length是使用int类型定义的,那么也就是说,String定义的时候,最大支持的长度就是int的最大范围值。
根据Integer类的定义,java.lang.Integer#MAX_VALUE的最大值是2^31 - 1;这个值约等于4G,在运行期,如果String的长度超过这个范围,就可能会抛出异常。(在jdk 1.9之前)
int 是一个 32 位变量类型,取正数部分来算的话,他们最长可以有
1 | 2^31-1 =2147483647 个 16-bit Unicodecharacter |
有近 4G 的容量。
很多人会有疑惑,编译的时候最大长度都要求小于65535了,运行期怎么会出现大于65535的情况呢。这其实很常见,如以下代码:
1 | String s = ""; |
得到的字符串长度就有10万,另外我之前在实际应用中遇到过这个问题。
之前一次系统对接,需要传输高清图片,约定的传输方式是对方将图片转成BASE64编码,我们接收到之后再转成图片。
在将BASE64编码后的内容赋值给字符串的时候就抛了异常。
后来为了解决这个问题,不再传输图片的BASE64编码内容了,而是先把文件上传到OSS或者FTP中,然后直接传递文件地址。
✅String中intern的原理是什么?
典型回答
字符串常量池中的常量有两种来源:
1、字面量会在编译期先进入到Class常量池,然后再在运行期进去到字符串池,
2、在运行期通过intern将字符串对象手动添加到字符串常量池中。
intern的作用是这样的:
如果字符串池中已经存在一个等于该字符串的对象,intern()方法会返回这个已存在的对象的引用。
如果字符串池中没有等于该字符串的对象,intern()方法会将该字符串添加到字符串池中,并返回对新添加的字符串对象的引用。
1 | String s = new String("Hollis") + new String("Chuang"); |
所以,无论何时通过intern()方法获取字符串的引用,都会得到字符串池中的引用,这样可以确保相同的字符串在内存中只有一个实例。
很多人以为知道以上信息,就算是了解intern了,那么请回答一下这个问题:
1 | public static void main(String[] args) { |
大家可以在 JDK 1.7以上版本中尝试运行以上两段代码,就会发现,s1 == s2的结果是 false,但是s3 == s4的结果是 true。
这是为什么呢?(后文所有case均基于JDK 1.8运行)
扩展知识
字符串常量进入常量池的时机
intern原理
先看一下上面这篇(让你看就去看,你不看,然后就看不懂这篇,就怪我讲的不清楚!哼,咋那么犟呢!?),了解了字符串常量进入常量池的时机之后,我们再回过头分析一下前面的例子:
1 | public static void main(String[] args) { |
这个类被编译后,Class常量池中应该有”a”和”aa”这两个字符串,这两个字符串最终会进到字符串池。但是,字面量”a”在代码①这一行,就会被存入字符串池,而字面量”aa”则是在代码⑦这一行才会存入字符串池。
以上代码的执行过程:
第①行,new 一个 String 对象,并让 s1指向他。
第②行,对 s1执行 intern,但是因为”a”这个字符串已经在字符串池中,所以会直接返回原来的引用,但是并没有赋值给任何一个变量。
第③行,s2指向常量池中的”a”;
所以,s1和 s2并不相等!
第⑤行,new 一个 String 对象,并让 s3 指向他。
第⑥行,对 s3 执行 intern,但是目前字符串池中还没有”aa”这个字符串,于是会把指向的String对象的引用放入字符串常量池
第⑦行,因为”aa”这个字符串已经在字符串池中,所以会直接返回原来的引用,并赋值给 s4;
所以,s3和 s4 相等!
而如果我们对代码稍作修改:
1 | String s = "aa";// ① |
以上代码得到的结果则是:false
第①行,创建一个字符串aa,并且因为它是字面量,所以把他放到字符串池。
第②行,new一个 String 对象,并让 s3 指向他。
第③行,对 s3 执行 intern,但是目前字符串池中已经有”aa”这个字符串,所以会直接返回s的引用,但是并没有对s3进行赋值
第④行,因为”aa”这个字符串已经在字符串池中,所以会直接返回原来的引用,即s的引用,并赋值给 s4;所以,s3和 s4 不相等。
a和1有什么不同
关于这个问题,我们还有一个变型,可以帮大家更好的理解intern,请大家分别在JDK 1.8和JDK 11及以上的版本中执行以下代码:
1 | String s3 = new String("1") + new String("1");// ① |
你会发现,在JDK 1.8中,以上代码得到的结果是true,而JDK 11及以上的版本中结果却是false。(有人反馈自己代码执行和我文中的不一样,可能的原因有很多,比如JDK版本不同、操作系统不同、本地编译过的其他代码也有影响等。故而如果现象不一致,可以使用一些在线的Java代码执行工具测试,如:https://www.bejson.com/runcode/java/ 。)
那么,再稍作修改呢?在目前的所有JDK版本中,执行以下代码:
1 | String s3 = new String("3") + new String("3");// ① |
得到的结果也是true,你知道为什么嘛?
✅try中return A,catch中return B,finally中return C,最终返回值是什么?
典型回答
最终的返回值将会是C!
因为finally块总是在try和catch块之后执行,无论是否有异常发生。如果finally块中有一个return语句,它将覆盖try块和catch块中的任何return语句。
1 | //无异常情况 |
所以在这种情况下,无论try和catch块的执行情况如何,finally块中的return C;总是最后执行的语句,并且其返回值将是整个代码块的返回值。
这个问题还有一个兄弟问题,那就是如下代码得到的结果是什么:
1 | public static void getValue() { |
原理和上面的是一样的,最终输出内容为3。
扩展知识
finally和return的关系
很多时候,我们的一个方法会通过return返回一个值,那么如以下代码:
1 | public static int getValue() { |
这个代码得到的结果是2,try-catch-finally的执行顺序是try->finally或者try-catch-finally,然后在执行每一个代码块的过程中,如果遇到return那么就会把当前的结果暂存,然后再执行后面的代码块,然后再把之前暂存的结果返回回去。
所以以上代码,会先把i++即2的结果暂存,然后执行i=100,接着再把2返回。
但是,在执行后续的代码块过程中,如果遇到了新的return,那么之前的暂存结果就会被覆盖。如:
1 | public static int getValue() { |
以上代码方法得到的结果是100,是因为在finally中遇到了一个新的return,就会把之前的结果给覆盖掉。
如果代码出现异常也同理:
1 | public static int getValue() { |
在try中出现一个异常之后,会执行catch,在执行finally,最终得到100。如果没有finally:
1 | public static int getValue() { |
那么得到的结果将是66。
所以,如果finally块中有return语句,则其返回值将是整个try-catch-finally结构的返回值。如果finally块中没有return语句,则try或catch块中的return语句(取决于哪个执行了)将确定最终的返回值。
✅while(true)和for(;;)哪个性能好?
典型回答
while(true)和for(;;)都是做无限循环的代码,他俩有啥区别呢?
关于这个问题,网上有很多讨论,说那么多没用,直接反编译,看看字节码有啥区别就行了。
准备两段代码:
1 | public class HollisTest { |
1 | public class HollisTest { |
分别将他们编译成class文件:
1 | javac HollisTest.java |
然后再通过javap对class文件进行反编译,然后我们就会发现,两个文件内容,一模一样!!!
1 | Classfile /Users/hollis/workspace/chaojue/HLab/src/main/java/HollisTest.class |
可以看到,都是通过goto来干的,所以,这两者其实是没啥区别的。用哪个都行
有人愿意用while(true)因为他更清晰的看出来这里是个无限循环。有人愿意用for(;;),因为有些IDE对于while(true)会给出警告。至于你,爱用啥用啥。
✅常见的字符编码有哪些?有什么区别?
典型回答
就像电报只能发出”滴”和”答”声一样,计算机只认识0和1两种字符,但是,人类的文字是多种多样的,如何把人类的文字转换成计算机认识的01字符呢,这个过程同样需要通过字符编码。
字符编码(Character encoding)是一套法则,使用该法则能够对自然语言的字符的一个集合(如字母表或音节表),与其他东西的一个集合(如号码或电脉冲)进行配对。
和摩尔斯电码功能类似,上个世纪60年代,美国制定了一套字符编码,对英语字符与二进制位之间的关系,做了统一规定,这被称为 ASCII 码,一直沿用至今。
由于ASCII只有128个字符,虽然对于英文字符都可以表示了,但是世界上还有很多其他的文字他是没办法表示的,所以需要一种更加全面的字符编码。
于是又出现了Unicode字符集(常见的Unicode Transformation Format有:UTF-7, UTF-7.5, UTF-8,UTF-16, 以及 UTF-32),除此之外还有一些常用的中文编码有GBK,GB2312,GB18030等。
扩展知识
Unicode和UTF-8有啥关系?
Unicode(中文:万国码、国际码、统一码、单一码)是计算机科学领域里的一项业界标准。它对世界上大部分的文字系统进行了整理、编码,使得计算机可以用更为简单的方式来呈现和处理文字。
Unicode备受认可,并广泛地应用于计算机软件的国际化与本地化过程。有很多新科技,如可扩展置标语言(Extensible Markup Language,简称:XML)、Java编程语言以及现代的操作系统,都采用Unicode编码。
Unicode是一套通用的字符集,包含世界上的大部分文字,也就是说,Unicode是可以表示中文的。
但是,Unicode虽然统一了全世界字符的编码,但没有规定如何存储。
因为如果Unicode统一规定,每个符号就要用三个或四个字节表示,因为字符太多,只能用这么多字节才能表示完全。一旦这么规定,那么每个英文字母前都必然有二到三个字节是0,因为所有英文字母在ASCII中都有,都可以用一个字节表示,剩余字节位置就要补充0。如果这样,文本文件的大小会因此大出二三倍,这对于存储来说是极大的浪费。
为了解决这个问题,就出现了一些中间格式的字符集,他们被称为通用转换格式,**即UTF(Unicode Transformation Format)。**常见的UTF格式有:UTF-7, UTF-7.5, UTF-8,UTF-16, 以及 UTF-32。
UTF-8 使用一至四个字节为每个字符编码
UTF-16 使用二或四个字节为每个字符编码
UTF-32 使用四个字节为每个字符编码
所以我们可以说,UTF-8、UTF-16等都是 Unicode 的一种实现方式。
有了UTF-8,为什么要出现GBK
因为UTF-8是Unicode的一种实现,所以他包含了世界上的所有文字的编码,他采用的是1-4字节进行编码。
对于那些排在前面优先纳入的文字,可能就优先使用1字节、2字节存储了,对于后纳入的文字,就要使用3字节或者4字节存储了。
正是因为UTF-8太全了,所以那些晚一些纳入的字符,在UTF-8中的存储所占的字节数可能就会多一些,那他的存储空间要求就会很大。
对于常用的汉字,在UTF-8中采用3字节进行编码,但是如果有一种只包含中文和ASCII的编码的话,就不需要使用3个字节,可能2个字节就够了。
对于大部分网站来说,基本都是只服务一个国家或者地区的,比如一个中国的网站,一般会出现简体字和繁体字以及一些英文字符,很少会出现日语或者韩文的。
也是出于这样的考虑,中国国家标准总局于1981年制定并实施了 GB 2312-80 编码,即中华人民共和国国家标准简体中文字符集。后来厂商微软利用GB 2312-80未使用的编码空间,收录GB 13000.1-93全部字符制定了GBK编码。
有了标准中文字符集,如果是一个纯中文网站,就可以可以采用这种编码方式,这样可以大大节省一些存储空间的。
常用的中文编码有GBK,GB2312,GB18030等,最常用的是GBK。
- GB2312(1980年):16位字符集,收录有6763个简体汉字,682个符号,共7445个字符;
- 优点:适用于简体中文环境,属于中国国家标准,通行于大陆,新加坡等地也使用此编码;
- 缺点:不兼容繁体中文,其汉字集合过少。
- GBK(1995年):16位字符集,收录有21003个汉字,883个符号,共21886个字符;
- 优点:适用于简繁中文共存的环境,为简体Windows所使用,向下完全兼容gb2312,向上支持 ISO-10646 国际标准 ;所有字符都可以一对一映射到unicode2.0上;
- 缺点:不属于官方标准,和big5之间需要转换;很多搜索引擎都不能很好地支持GBK汉字。
- GB18030(2000年):32位字符集;收录了27484个汉字,同时收录了藏文、蒙文、维吾尔文等主要的少数民族文字。
- 优点:可以收录所有你能想到的文字和符号,属于中国最新的国家标准;
- 缺点:目前支持它的软件较少。
为什么会出现乱码
文件里面的内容归根到底都是有0101组成的,至于0101的二进制码如何转成人们可以理解的字符串,则是需要通过规定好的字符编码标准进行转换才可以。
我们把一串中文字符通过UTF-8进行编码传输给别人,别人拿到这串文字之后,通过GBK进行解码,得到的内容就会是“锟届瀿锟斤拷雮傡锟斤拷直锟斤拷锟”,这就是乱码。
✅泛型中K T V E ? Object等分别代表什么含义。
E – Element (在集合中使用,因为集合中存放的是元素)
T – Type(Java 类)
K – Key(键)
V – Value(值)
N – Number(数值类型)
? – 表示不确定的java类型(无限制通配符类型)
S、U、V – 这几个有时候也有,这些字母本身没有特定的含义,它们只是代表某种未指定的类型。一般认为和T差不多。
Object – 是所有类的根类,任何类的对象都可以设置给该Object引用变量,使用的时候可能需要类型强制转换,但是用使用了泛型T、E等这些标识符后,在实际用之前类型就已经确定了,不需要再进行类型强制转换。
扩展知识
代码示例
1 | // 示例1:使用T作为泛型类型参数,表示任何类型 |